


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双目视差机制的视频图像超分辨率重建
[郝贵举1  , 杨洪臣
, 杨洪臣1 , 颜瑞彬2 ]
, 杨洪臣|
|


第一作者简介:郝贵举,女,辽宁营口人,硕士研究生,研究方向为视频侦查与图像检验技术。E-mail: haoguiju23@163.com
针对公安实践中成像质量较差的视频图像,基于双目视差机制进行超分辨重建。本文提出用视频中相近时段的两帧图像代替双目图像,即将摄像机位置固定,物体连续运动形成视差不同的视频图像,截取视频中同一运动物体不同时间的两帧图像作为双目图像。采用双目视差机制以及残差网络模型实现视频图像的超分辨率重建。通过多尺度特征提取、视差注意模块、超分辨率重建模块,获得图像的高频信息。结果表明,相较于传统方法,本文方法峰值信噪比提升1.27dB,结构相似性指标提升0.004,主观视觉效果上可以观察出视频图像明显清晰,减少了边缘模糊。基于双目视差机制的视频图像超分辨率重建的方法视觉效果上增加了清晰度,超分辨效果良好。
Due to the influence of photograph-taking conditions including distance, competence of monitoring equipment and blurring from the moving objects, the relevant video images are frequently rendered into poor visual quality, making them difficult to either recognize or meet the investigative requirements for public security. Therefore, a super-resolution reconstruction is here proposed about video image based on binocular parallax mechanism. Particularly, with the camera fixed at a position, the tested moving object is to have its continuous motion kept into images of different parallax against which two time-different frames of the object's picture are placed as binocular images into the adopted network model. The image is extracted of its multi-scale information with the feature extraction module outfitting improved atrous spatial pyramid pooling, followed to have its effective information obtained through introduction into the parallax attention module and successively its super-resolution right/left image (frame) reconstructed via the residual network. Finally, the deconvolution is operated to visualize the convolution process. The experimental results show that the output image, compared with the resultant from traditional video image super-resolution reconstruction, has increased its peak's signal-to-noise ratio by 1.27 db, enhanced its structural similarity index by 0.004, with its subjective visual effect being obviously clear and its edge blur reduced, hence demonstrating that the excellence is present of the here-adopted video image super-resolution reconstruction based on binocular parallax mechanism. A new idea is thus provided for improving video image's resolution with such a manipulation of replacing binocular images with two frames taken at similar-yet-different time points in a video and combination of the convolutional neural networks for super-resolution. The approach adopted here can also be applied to recover low-resolution video images exampled as those handled in this article about recognition of one person's portrait and a car's registration plate. Certainly, the method proposed here uses only two frames of video images, and its feature extraction of image has some limitations, too. Accordingly, the next and/or future work may consider into taking multi-frame images of one moving object at different time points and improving the performance with image feature extraction.
超分辨率技术(super-resolution)就是将低分辨率(low-resolution)的单幅或同一场景的多幅图像经过一定的算法提升到高分辨率(high-resolution), 增加图像的像素密度, 丰富细节信息, 增强视觉效果。在公安刑侦工作中, 高分辨率的视频图像对于后期进行针对性视频分析工作至关重要。这项技术能够克服硬件系统、拍摄环境的局限, 能够低成本、高效率为公安侦查工作提供可靠方向。
随着图像处理技术的发展, 超分辨技术逐步得到国内外学者的广泛探索与深入研究, 取得了丰硕的成果。目前, 超分辨算法大致可以分为基于插值、基于重建以及基于学习三种[1]。基于插值的方法就是通过低分辨率的像素点与周围的信息进行插值, 重构图像, 以达到高分辨重建的效果, 是最传统也是最简单的方法。然而, 放大倍数较大时, 图像出现明显的边缘模糊化, 视觉效果较差。基于重建的方法, 就是依据低分辨率图像的退化模糊的先验原理, 逆向推断成像过程, 进行超分辨重建。基于学习的方法就是通过训练数据, 使机器学习高分辨率和低分辨率图像的映射关系, 然后针对低分辨率图像, 依据建立的映射关系获得高分辨率图像。目前, 基于学习的方法结合神经网络对低分辨率图像做处理, 在重建质量和速度方面表现出强大的优势, 得到广大学者的关注和认可。2016年香港中文大学Dong等[2]提出卷积神经网络模型(super-resolution convolutional neural network, SRCNN), 首次将卷积神经网络应用于单幅图像的超分辨率重建上, 与传统算法相比, SRCNN客观性能指标和主观视觉评价上有了很大的提高。为了达到实时超分辨效果, Dong 等[3]在改进SRCNN基础上提出了一种更加紧凑的深度卷积神经网络模型(fast super-resolution convolutional neural network, FSRCNN), 在网络的最后引入反卷积层。为了提高超分辨质量, Wang[4]和Liu[5]提出了将稀硫编码与深度学习相结合实现快速训练, 提升了图像的鲁棒性能。此外, 在视频超分辨研究领域, Liao[6]提出将光流方法与卷积神经网络相结合获得高分辨率视频帧, 加快视频重建速度。Caballero[7]提出了一种基于空间变压器网络的运动补偿机制的时空亚像素卷积网络(VESPCN), 减少了时空网络计算, 提高了重建的准确度。Wang等[8]提出了一种结合残差块的增强型视频超分辨网络(EVSR), 利用时空信息获取连续帧之间运动关系, 结合残差学习提升网络收敛速度, 预测高频细节
信息。
本文提出将视频中相近时段的两帧图像代替双目图像, 即截取视频中同一运动物体不同时间的两帧图像作为视差不同的双目图像, 输入网络模型中, 利用双目图像的较大视差, 结合残差网络结构, 视差注意力机制, 对输入的低分辨率的图像进行超分辨率重建, 获取高频信息。与传统方法相比, 本文使用的网络模型在客观性能上和主观视觉效果上均有显著提升, 为基于学习提升视频图像超分辨率提供一种思路, 在公安实践中有较大的运用前景。
人眼从两个不同角度观察相同物体, 会得到不同的物体信息, 再经过大脑进行处理可以获得空间物体的三维信息。根据人眼原理, 在计算机中建立双目立体视觉系统, 运用三维重建技术, 对输入物体的双目图像进行处理, 得到物体空间信息。
双目立体视觉的原理就是将两台摄像机放置在不同位置, 以不同视角同时拍摄同一空间物体, 根据成像原理获得两个二维平面图像, 计算空间点映射到左图与右图像素上坐标偏差, 获得物体的三维空间信息。
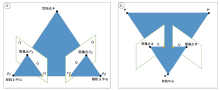
对极几何就是表示两幅图像间的内部射影关系, 与外部环境无关。它表示图像平面与平面束相交构成的几何。
如图1a所示, 如果得到三维空间点P在图像I1上的投影点是P1, 则这个点在图像I2上的投影一定会在l2这条极线上。当P1在O1P向量上, 其在I2的投影都在l2这条极线上, 根据这个几何特性, 当已知P1时, 可以在l2上找到P2。反之同理, 这就是对极约束。将对极几何中的极线约束应用在图像超分辨的重建中, 可以集成低分辨率双目图像的有效信息, 但拍摄立体图像对时, 对环境光照非常敏感, 受光照角度、强度变化的影响, 拍摄的两张图片亮度差别会比较大, 而且两台摄像机的位置要水平放置在同一基准面上, 且需要同时拍摄, 并保证两台摄像机的光轴是平行的, 无疑为双目图像的获取增加了难度。因此, 提出截取视频中同一运动物体相近时段的两帧图像作为双目立体图像的方法。
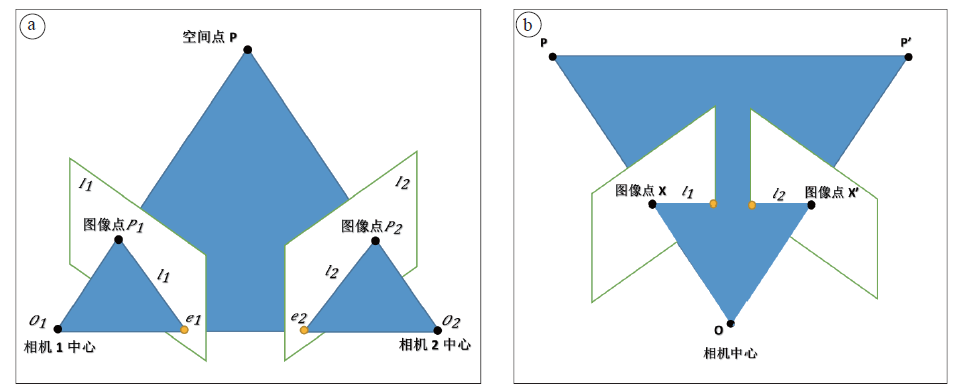 | 图1 对极几何(a)与仿对极几何(b)约束图Fig. 1 Illustration of constraint relationship about epipolar geometry (a) and its imitating alternative (b) |
如图1b所示, 监控视频的摄像机固定在一点o, 运动物体从P运动到P', 先截取运动物体在P点的图像相当于传统双目立体图像中右视角拍摄图像, 再截取物体运动到P'点处的图像相当于传统双目立体图像中左视角图像, 因此得到视差不同的双目图像。图像点X和X'和摄像机中心o以及空间点P和P'五个点是共面的, 构成平面π , 是最本质的约束。当已知图像点X, 由于X和X'一定在平面π 上, π 可以利用图像点的反投影射线以及空间点运动基线PP'确定, 图像点X'是右侧图像平面上的点, 因此, X'一定位于平面π 与右侧图像平面的交线l2上, 因此构成约束。
该方法相对于传统运用两台摄像机拍摄双目图像的方法, 可以保证两张图像拍摄的相机内部参数完全相同, 可以更好地控制拍摄条件, 确保拍摄环境的相对一致性, 双目图像的获取更加便利。
目前, 超分辨评价准则标准包括主观评价和客观评价。主观评价依据人眼的视觉感受, 对图像的优劣作出主观的评价。客观的量化方法包括峰值信噪比(PSNR)以及结构相似性(SSIM)。PSNR是计算图像内像素最大值与加性噪声功率的比值, 它基于处理后的图像与原图像对应像素点间误差, PSNR值越高, 表示图像失真越小, 说明超分辨重建图像的质量与高分辨图像的质量越接近, 图像效果越好, 其计算方法如公式(1)所示:
$P S N R=10 \times \log _{10}\left(\frac{M A X_{1}^{2}}{M S E}\right)=20 \times \log _{10}\left(\frac{M A X_{1}}{\sqrt{M S E}}\right) $ (1)
其中, MAX1表示图像中像素值的最大值, MSE表示原始图像X与处理后图像Y之间的均方误差, 其公式计算如下:
$M S E=\frac{1}{C \times H \times W} \sum_{k=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}(X(i, j, k)-Y(i, j, k))^{2} $ (2)
SSIM是评价原始图像与处理图像之间的结构度、亮度和对比度的相似性, SSIM值趋近于1, 说明两幅图像相似, 重建效果越好。其计算公式如下:
$\begin{array}{l} L(X, Y)=\frac{2 \mu_{X} \mu_{Y}+C_{1}}{\mu_{X}^{2}+\mu_{Y}^{2}+C_{1}} \quad C(X, Y)=\frac{2 \mu_{X} \mu_{Y}+C_{2}}{\mu_{X}^{2}+\mu_{Y}^{2}+C_{2}} \\ S(X, Y)=\frac{\sigma_{X Y}+C_{3}}{\sigma_{X} \sigma_{Y}+C_{3}} \\ S_{S S I M}(X, Y)=L(X, Y) \times C(X, Y) \times S(X, Y) \end{array}$(3)
其中, μ X和μ Y为图像X、Y的像素均值, σ X和σ Y为图像X、Y的像素标准值, σ XY表示图像X和图像Y的协方差。C1、C2、C3为常数。C1=(K1× L)2, C2=(K2× L)2, $ C _{3}=\frac{C _{2}}{2}$, 一般的, K1=0.01, K2=0.03, L=255。
网络的训练样本包括输入图像的低分辨率以及高分辨率的标签图两部分组成。首先要对原始样本集进行下采样, 使用双三次插值法获取低分辨图像集。其次, 对原始样本集和低分辨图像集扩充, 采用不同尺寸的滑动窗口对图像切割, 得到若干90× 30的低分辨率图像块和360× 120高分辨率图像块作为训练集。
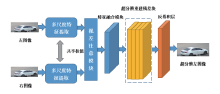
如图2所示, 所采用的总体方案主要由四部分构成, 分别为多尺度特征提取、视差注意模块、残差学习、反卷积。
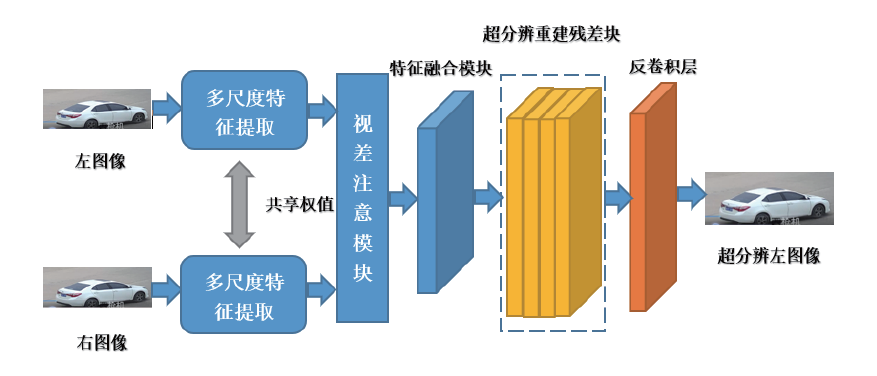 | 图2 总体设计方案流程图Fig. 2 Flow chart of overall scheme about super-resolution into image |
2.2.1 多尺度特征提取
提取图像的上下文信息在图像的超分辨重建过程中至关重要, 是有效恢复高频信息的关键。Chen等[9]对空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)结构进行了改进, 这样可以更好处理特征大小的问题。
本文将改进的ASPP思路运用到图像的超分辨的特征提取过程中, 可以表达图像的多尺度特征。
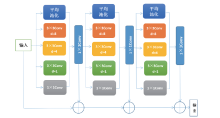
改进的ASPP模块包括一个核为1× 1的卷积层, 三个核为3× 3的卷积层, 以及一个全局平均池化层。增加的1× 1卷积层可以提取图像的大范围特征, 这样防止3× 3卷积层的膨胀率过大丢失边缘特征的信息; 三个3× 3的卷积通过采用不同的膨胀率(膨胀率分别采用1、4、8), 得到图像的多尺度特征; 平均池化层可以获取图像的全局特征。这样就可以获取图像的局部特征以及背景全局特征, 为下一层网络提供了图像的多尺度特征信息。图3为多尺度特征提取模块流程图。
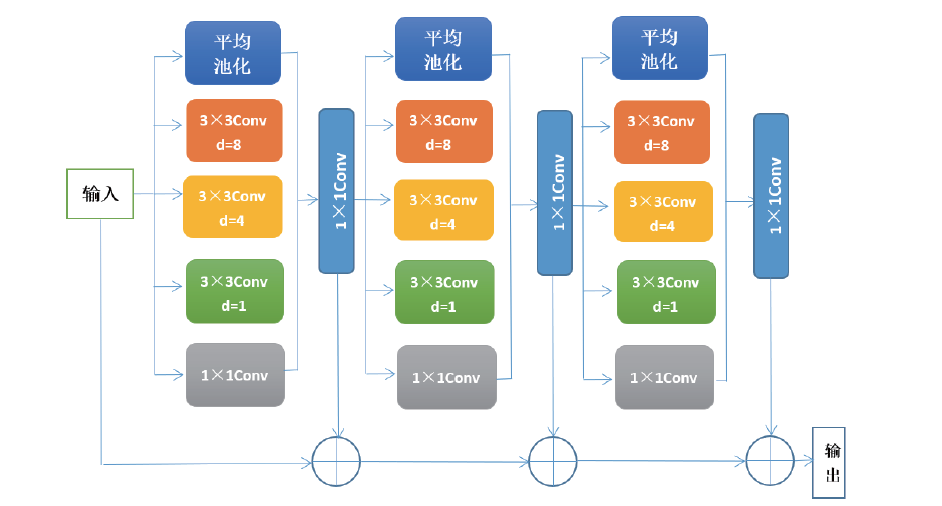 | 图3 多尺度特征提取模块流程图Fig. 3 Operational mode of multi-scale feature extraction module |
2.2.2 视差注意模块
深度学习中注意力机制是借鉴人类的注意力机制, 关注所需要的目标区域, 获取图像重点信息, 抑制无关信息。注意力机制一般通过掩码实现。掩码(mask)就是利用一层新的权重, 标识出图片中重点细节信息, 机器学习训练后, 使网络模型学习到图片中重点关注目标区域。
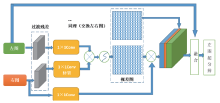
针对双目图像, PASSRnet模型中提出一种视差注意力机制, 其中视差提取模块沿极线具有全局感受野, 然后运用对极几何中的极线约束, 获取双目图像之间无遮挡的有效信息[10]。如图4是视差注意模块的流程图。
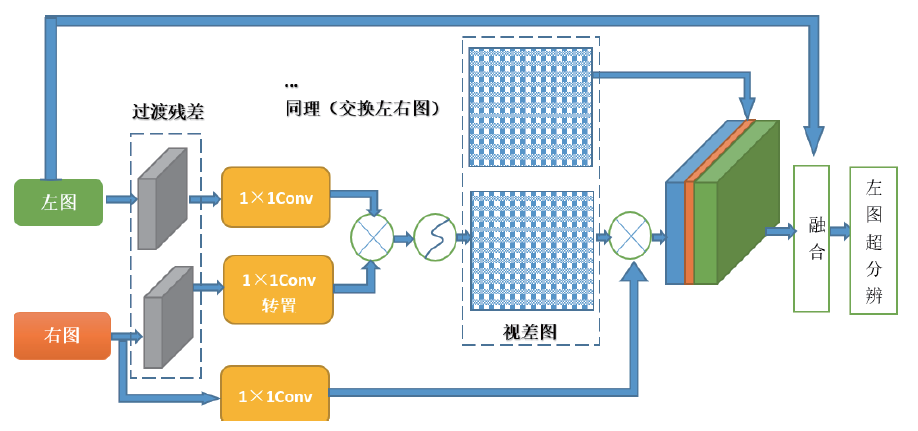 | 图4 视差注意模块流程图Fig. 4 Work route of parallax attention module |
将获取的特征图左图(ML)与右图(MR)通过一个过渡残差块, 得到ML'和MR', 再将ML'输入1× 1的卷积层得到L, MR'输入1× 1卷积层转置后得到R。将L和R进行批次化矩阵相乘, 得到视差注意力图M。同时MR通过1× 1卷积层得到A, 再将M与A进行批次化矩阵相乘得到O。将左右图交换, 重复上述过程, 最终将得到的特征图通过1× 1卷积融合, 得到最终左右图特征融合后的结果。
2.2.3 残差学习
超分辨重建过程采用了4个残差模块对特征融合后的张量进行卷积操作。由于神经网络的深度对图像的重建效果会产生较大的影响, 并不是神经网络的深度越深, 结果越好。对于传统的卷积神经网络随着深度的不断加深, 梯度消失现象出现, 数据训练的准确性趋于平缓, 训练误差会变大。为了解决这种退化现象, Kim等[11]提出了残差学习(ResNet)。残差学习的数学表达式如下:
$F=W_{2} \sigma\left(W_{1} x\right) \quad y=F\left(x, W_{i}\right)+x$
其中, x和y分别为残差块的输入和输出向量, Wi表示第i层卷积的权重(图5示意为两层), σ 表示Relu激活函数, 为方便起见, 表达式中省略了偏置, 采用恒等映射, 这样没有引进额外参数。F(x, Wi)是要学习的残差映射。为实现输入与输出同等映射, 应使残差趋近于0, 这样可以表示在深度网络下, 网络的权重训练已经达到最优, 其余的网络的层数不会使网络的学习精度下降。因此, 采用两个卷积层组成一个残差块, 每一层卷积由64个3× 3的滤波器构成, 激活函数采用LeakyRelu。图5所示为残差学习的基本思路。
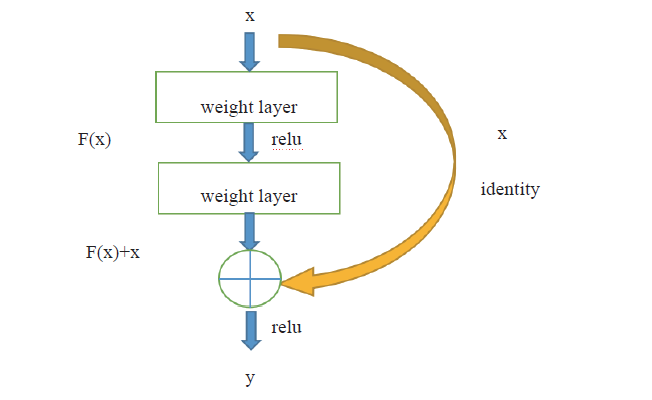 | 图5 残差学习网络图Fig. 5 Convolutional evolution with residual learning network |
2.2.4 反卷积
反卷积也称为转置卷积。输入图像通过卷积网络提取特征, 输入的尺寸会变小, 图像经过超分辨重建后, 输出图像需要将图像恢复到原来的尺寸以便进行对比观察, 因此利用反卷积层将卷积过程可视化。反卷积过程首先对输出图像自动填充补0, 增大图像尺寸, 再将卷积核旋转, 最后正向卷积。因此, 通过反卷积层对特征张量进行反卷积操作, 反卷积层由64个3× 3的滤波器构成。反卷积层可以将特征张量映射到RGB空间, 扩大图像尺寸, 最终得到可视化的输出图像。
实验所采用的仿真平台为pycharm, 硬件设备为Intel Core i5 型号的处理器和NVIDIA GeForce GTX 1080 Ti GPUFR 计算机, 内存为32 GB。CUDA Toolkit的版本为9.0, 训练数据集采用双目图像公开数据集Flickr1024数据集中的800张多场景图像。
测试数据集选用KITTI2012测试集中的100幅图像、KITTI2015 测试集中的20幅图像以及真实视频中截取的20幅图像。
采用Adam优化函数对网络进行优化, 迭代次数为90次, 初始学习率设置为0.000 2, 当训练每间隔30次, 学习率降低为原来的一半。
现将本文算法分别与Bicubic算法、SRCNN算法、VSRnet[12]算法以及VESPCN算法进行主观与客观比较, 验证其有效性。将测试数据集图像尺寸分别放大2倍和4倍后, 图像超分辨客观比较结果如表1所示。
| 表1 测试集的平均PSNR(dB)和SSIM的比较 Table 1 Comparison of different algorithms with test set about their resultant mean PSNRs (dB) and SSIMs |
从表1中可以看出, 本文方法对视频图像的超分辨重建中, 放大倍数增大, PSNR和SSIM指标降低, 重建质量下降。与SRCNN方法比较, 图像放大2倍时PSNR提升1.27 dB, SSIM提升0.004, 主要原因为相比于SRCNN针对单幅图像进行超分辨, 本文采用双目图像作为输入图像, 可以充分利用左右目图像信息, 使特征更为丰富。相比于VSRnet和VESPCN在图像放大2倍的情况下, 本文的结果较好, 其原因主要为采用ASPP网络对输入图像进行多尺度特征提取, 使得网络可以学习不同感受野的特征信息, 恢复更多的丢失细节信息。此外, 采用的视差注意机制能有效集成双目图像中左图的有用信息, 同时采用残差学习, 使网络具有泛化性能, 可以学习不同维度残差特征, 从而获得丰富的纹理信息, 重建效果更好。
为检验本文算法对于公安实践中视频图像的应用价值, 从实际案件中的监控视频画面截取两帧图像作为实验样本, 本文算法与其他几种经典的图像和视频超分辨算法重建效果进行对比, 图6为放大2倍的情况下不同算法的超分辨结果。
 | 图6 超分辨重建结果图(放大2倍)Fig. 6 Super-resolution reconstruction into the image of a car's registration plate (zoomed twice) |
公安工作中另一种经常出现的视频图像就是对人像的识别。例如, 银行的ATM取款机通过鱼眼镜头所拍摄到的人像信息, 受到拍摄环境的限制, 得到的视频图像中曝光不足导致人像模糊, 因此通过截取不同视差的双目图像作为网络的输入图像, 对低质量的人像进行超分辨重建, 为公安侦查工作提供方向。图7为放大4倍的情况下不同算法的人像超分辨结果图。
 | 图7 超分辨重建结果图(放大4倍)Fig. 7 Super-resolution reconstruction into the image of one person's face (zoomed four times) |
对图6、7中红框表示的区域放大, 进行细节纹理的对比, 可以观察出本文算法优于VSRnet、VESPCN和SRCNN算法。图6中车牌数字和字母的棱角边缘可以观察出, 本文方法的重建视觉效果更为清晰, 重建的车牌中棱角边缘形状更接近于真实图像。图7中由于是ATM机前镜头拍摄, 图像光线较暗, 但可以看出本文算法相比于传统算法, 重建效果明显清晰。因此, 本文所采用的超分辨重建算法应用于视频图像可以恢复图像更多的细节信息, 视觉效果上增加了图像的清晰度, 超分辨效果较好。
将视频中相近时段截取的两帧图像代替双目图像, 结合卷积神经网络进行超分辨为提高视频图像分辨率提供了一种新思路。双目图像的获取方法更加便利、准确、便捷。实验结果表明, 相较于一些传统的视频超分辨重建方法, 本文模型性能在客观指标和主观视觉效果上均有较好的结果, 能恢复更多图像的高频信息, 减少图像边缘模糊。在未来工作中, 可以深度挖掘该模型的实用价值, 应用到公安侦查工作中的人像监控识别、车牌监控识别、行车记录仪等低分辨率的视频图像的重建, 提高办案效率。
本文提出的方法虽然在视频图像超分辨率重建上取得了较好的结果, 但只采用视频中的两帧图像, 图像特征提取范围具有一定的局限。接下来研究中, 考虑截取同一运动物体不同时段的多帧图像, 输入网络, 多次迭代, 进一步提高图像分辨率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|