


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于miRNA相对表达量自动判别月经血和外周血
[王国力1, 2  , 刘扬
, 刘扬3 , 何红霞1, 4 , 季安全1 , 张伟2 , 曹洋3, * , 孙启凡1, * ]
, 刘扬, 孙启凡]
|
|


第一作者简介:王国力,女,山东荣成人,硕士研究生,研究方向为法医遗传学。E-mail: wangguoli1996@sina.com
目的 探索有效区分月经血和外周血的miRNA最优标记组合及最佳分类模型,并构建简便快速的自动化判别软件。方法 对10种miRNA(miR-451a、miR-205-5p、miR-203a-3p、miR-214-3p、miR-144-3p、miR-144-5p、miR-654-5p、miR-888-5p、miR-891a-5p、miR-124-3p)在200余份月经血和外周血样本中的相对表达量以实时荧光定量PCR检测,并以7种算法模型(核密度估计、K-最近邻、逻辑回归、线性判别分析、支持向量机、神经网络、随机森林)进行数据分析,选出鉴别效果最好的标记组合及算法模型,进而构建自动判别软件。结果 月经血和外周血中差别最大的三种miRNA为miR-205-5p、miR-203a-3p和miR-214-3p,使用miR-144-5p与上述miRNA中的一种或两种组合可达较好区分效果,其中基于miR-144-5p、miR-203a-3p和miR-205-5p所形成的“最优特征项组合一”稳健性最强。7种算法模型中最佳分类模型为核密度估计模型,其次为逻辑回归模型。结论 本研究建立的自动判别软件界面友好、使用简单,适合辅助法医检验关于月经血和/或外周血判别分析的计算,便利于法医物证工作,有较大的推广应用价值。
Objective To explore the optimal combination of miRNA markers and classification model for effectively distinguishing menstrual from peripheral blood so as to build up one piece of simple and fast automatic discriminant software.Methods 10 kinds of miRNAs (miR-451a, miR-205-5p, miR-203a-3p, miR-214-3p, miR-144-3p, miR-144-5p, miR-654-5p, miR-888-5p, miR-891a-5p, miR-124-3p) were analyzed through quantitative real-time PCR into their relative expression quantities from menstrual (104 pieces) and peripheral (136 pieces) blood samples. Seven algorithmic models (kernel density estimation, K-nearest neighbor, logistic regression, linear discriminant analysis, supportive vector machine, neural network, random forest) were used for data analysis so that both the optimal miRNA marker combinations and appropriate algorithmic models were selected. Consequently, the software was therewith to construct for automatically distinguishing menstrual from peripheral blood with better identification effect.Results Three miRNAs of miR-205-5p, miR-203a-3p and miR-214-3p were of greatest difference between menstrual and peripheral blood, hence coming forth the better/optimal combinations of one or two of them assembling with miR-144-5p. Among the optimal combinations, the recommended one of miR-144-5p, miR-203a-3p and miR-205-5p demonstrated most robust. The appropriate classification model was the kernel density estimation for all the seven algorithmic ones, with the logistic regression being followed.Conclusions The automatic discriminant software constructed in this study is of friendly interface, simple use, accurate and reliable server algorithm, suiting for assisting forensic calculation on menstrual and peripheral blood identification, therefore capable of effectively facilitating the forensic analysis of evidential materials and great value of promotion and application.
犯罪现场遗留的体液样本类型及来源的判定, 对犯罪行为分析、重建犯罪现场至关重要[1]。血液是犯罪现场常见的体液类检材, 其准确定性可为案件侦破提供重要线索, 因此寻找简便快速鉴别血液样本类型(如外周血还是月经血)的方法对于法医实践意义重大[2]。
微RNA(MicroRNA, miRNA)是具有调控功能的非编码RNA, 其大小约为20 ~ 25个核苷酸, 能附着在编码蛋白质的mRNA链上而抑制新蛋白的转录[3, 4]。miRNA具有长度短、表达量高和稳定性好等特点, 已被证实可用于各种体液类型的鉴定[5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]。miRNA在不同体液中的表达特异性主要体现在其表达量上的差异, 通过定性鉴定很难对其准确区分判断, 因此越来越多的实验室开始使用数学算法模型对miRNA的相对表达量进行综合分析, 以期得出更科学可靠的结论[6, 7, 14, 16]。
本研究建模以外周血和月经血为样本, 经实时荧光定量PCR技术获取不同miRNA分子在各样本中的相对表达量而组成分析数据集。选取7种模型算法即核密度估计(kernel density estimation, KDE)、K-最近邻(K-nearest neighbor, KNN)、逻辑回归(logistic regression, LOG)、线性判别分析(linear discriminant analysis, LDA)、支持向量机(supportive vector machines, SVM)、神经网络(neural network, NN)、随机森林(random forest, RF), 基于相同的数据集样本进行分析计算。最终选用核密度估计和逻辑回归作为后台算法模型开发软件, 通过miR-144-5p、miR-203a-3p、miR-205-5p三种miRNA的相对表达量数据进行未知样本的类型判定计算, 可实现外周血、月经血的自动判别。
来自中国北方25 ~ 35周岁健康成年人外周血样本136份, 25 ~ 35周岁健康成年女性月经血样本104份。样本的收集均符合知情同意原则并已通过公安部物证鉴定中心伦理委员会审查[19]。
根据已报道的多篇研究文章, 挑选出10种候选miRNA ( miR-451a[6, 8, 9, 10], miR-205-5p[6, 12, 13], miR-203a-3p[6, 7, 12, 13], miR-214-3p[6, 8, 11], miR-144-3p[13], miR-144-5p[14], miR-654-5p[13, 15], miR-888-5p[8, 11, 16], miR-891a-5p[8, 11, 16], miR-124-3p[7, 17] ) 进行此研究工作, 使用RNU6b[6, 18] 作为内参基因对数据进行归一化, 以确保结果的科学合理性[20]。
采用miRNeasy Mini Kit(Qiagen, 德国)试剂盒, 按说明书提取样本中的总RNA。用Nanodrop2000c和Qubit 4荧光定量仪(Thermo Fisher Scientific, 美国)进行总RNA浓度和纯度的测定[12]。对定量后的RNA进行逆转录后, 使用SYBR Green法对提取的miRNA及内参RNU6b同时进行qPCR检测, 以获取相对表达量数据。使用Δ Ct值代表miRNA的相对表达量, 用于训练和验证分类模型数据变量。
Δ Ct =Ct(miRNA)-Ct(RNU6b) (1)
研究共选取7种模型算法, 基于相同的数据集样本进行分析计算。KDE是一种非参数估计方法, 可以根据数据样本本身研究数据分布规则, 并根据给定的样本集求解随机变量的分布密度函数。KNN基于每个查询点的k个最近邻居执行学习, 其中k是用户指定的整数, 本研究选2。LOG是用于分类而不是回归的线性模型, 其描述的可能结果的概率使用logistic函数对单个试验进行建模。LDA可用于执行有监督的降维, 该线性子空间包含使类之间距离最大化的方向, 并且还可以使用贝叶斯规则和概率密度函数将降维数据用于分类。SVM属于监督学习方法, 它使用训练点的子集作为决策边界(称为支持向量)。NN方法为多层感知器, 是一种有监督的机器学习算法, 可学习用于分类或回归的非线性函数。在多层感知器的输入和输出层之间, 可以存在一个或多个非线性层, 称为隐藏层。本研究设置一个隐藏层, 其由10个神经元组成。RF是一种通过集成学习的思想整合多个决策树的算法。在RF中, 每个决策树都是一个分类器, 然后对于一个输入样本集, 每个树都将具有一个分类结果, 并最终整合所有分类投票结果, 而以指定投票数最多的类别作为最终输出。
根据体液的类型和来源, 用于训练模型的样本分为外周血(136份)和月经血(104份)。这些训练样本的替代特征包括miR-451a、miR-205-5p、miR-203a-3p、miR-214-3p、miR-144-3p、miR-144-5p、miR-654- 5p、miR-888-5p、miR-891a-5p和miR-124-3p的Δ Ct值。为避免过拟合的风险, 使用五重交叉验证方法来评估分类器性能。将样本集随机分为五个子集, 同时确保每个子集中每种体液样本的比例一致, 并使用其中四个对模型进行训练, 然后在其余子集上验证训练后的模型。此过程将执行五次, 以便每个细分都有机会成为测试集, 并且将五个模型的平均性能用于最终评估。评估模型的标准包括:
1)精确率(precision)
预测结果为阳性的样本中真阳性样本所占的比例。
$precision = \frac{TP}{TP+FP}$ (2)
式中, TP (true positive)表示真阳性样本, FP (false positive)表示假阳性样本, 下同。
2)召回率(recall)
所有阳性样本中预测正确的比例。
$recall = \frac{TP}{TP+FN}$ (3)
式中, FN (false negative)表示假阴性样本, 下同。
3)F1值(F1-score)
精确率和召回率的调和平均数, 最大为1, 最小为0。F1值随着数据扰动程度的增大而减小, 可通过其变小的速度反映模型预测的准确性, 减小的速度越快, 模型的稳健性越差。
$F1-score =2 \frac{precision* recall}{precision+recall}$ (4)
4)准确率(accuracy)
预测结果正确的百分比。
$accuracy = \frac{TP+TN}{TP+TN+FP+FN}$ (5)
式中, TN (true negative)表示真阴性样本, 下同。
5)马修斯相关系数(Matthews correlation coefficient, MCC)
用于衡量二分类问题, 综合考虑了TP、TN、FP、FN, 是一个比较均衡的指标。MCC的取值范围在[-1, 1], 取值为1表示预测与实际完全一致, 取值为0表示预测的结果类似于随机预测, -1表示预测结果与实际的结果完全不一致。
$MCC = \frac{TP× TN-FP× FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}$ (6)
6)受试者工作特征曲线下面积(area under the receiver operating characteristic curve, AUC)
反映分类器的分类性能。
该软件最终选择用于建模的算法包括核密度估计(KDE)和逻辑回归(LOG)。基于以上两种方法构建二分类器, 通过实验筛选出具有体液特异性的miRNA分子, 最终确定获得最佳预测精度的最优分类方法。软件运行环境:1)硬件环境:X86/64 CPU 1GHz以上, 内存1 GB以上, 硬盘10 GB以上; 2)操作系统:Win10(64位); 3)编程语言:Python; 4)编译器:CPython3.6.3。
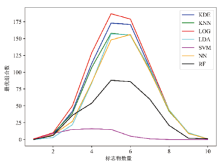
为更方便在法医鉴定中进行应用, 并降低分类器的复杂性以使其更稳定, 同时确保良好的分类性能, 需选择上述miRNA标记分子的较小子集作为最终使用的标记组合。为了确定适当的标记数量来构建具有低复杂度和高性能的模型, 采用依次增加标记数量的方法, 并检查每个标记的所有可能组合。将上述10种miRNA按照一定的数目进行组合, 对于每一种组合, 分别基于材料与方法中的7种方法进行模型的训练和测试。分别从每种组合数目的模型中选出测试准确性(采用MCC和AUC进行衡量)最高的一组模型, 考察不同数目的miRNA标记所构建模型的准确性差异情况(图1), 可见当标记数目为1时, 只有LOG方法构建的模型中存在一个能够完全鉴别外周血和月经血的模型, 该模型所用的分子标记为miR-203a-3p, 但是对该模型重复100次的测试结果发现, 该模型能够完全鉴别外周血和月经血的概率只有81%, 无法满足实际应用需要, 故排除只用一种miRNA鉴别外周血和月经血的可能性。
 | 图1 不同数目miRNA标记构建的模型准确性图(A:MCC值与标志物数量的关系; B:AUC值与标志物数量的关系; C:10种miRNA在外周血和月经血中的表达差异情况)Fig.1 Accuracy obtained from each algorithmic model to analyze quantity-different miRNA markers versus MCC (A) and AUC (B), and different expression of 10 miRNAs in peripheral blood and menstrual blood (C) |
分别统计每种方法构建的组合中能够完全鉴别出外周血和月经血的模型数目, 发现逻辑回归方法表现最好, 其次为核密度估计, 结果见图2。因此最终开发软件选择基于这两种方法。
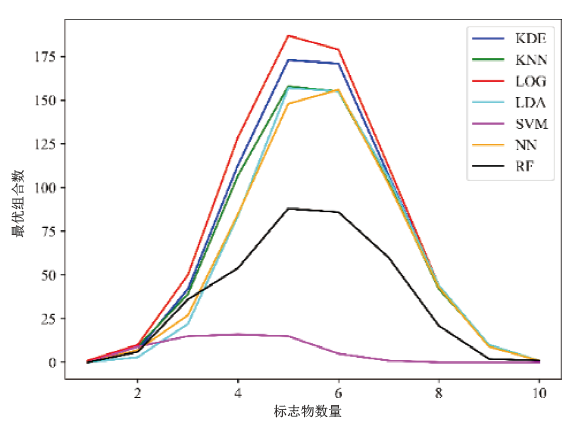 | 图2 不同方法构建的模型中能够完全鉴别外周血和月经血的模型数目统计图Fig.2 Statistical presentation of the combinations capable of complete discrimination between peripheral and menstrual blood with the models constructed by choice-various methods |
选用差异性最大的miR-205-5p、miR-203a-3p以及miR-214-3p进行两两组合, 验证使用两种miRNA进行外周血和月经血区分的能力, 结果发现虽然都能够较好区分外周血和月经血, 但由于月经血中存在明显的离群值, 导致单独使用这三种组合中的某一种区分外周血和月经血都不能达到理想的效果。
进一步将其他miRNA与这三种miRNA(miR-205-5p、miR-203a-3p、miR-214-3p)中的一种组合却能达到很好的鉴别效果。所有由两种标记构建的模型中, 一次测试结果能够完全鉴别外周血和月经血的组合有13组:miR-205-5p/miR-124-3p, miR-144-3p/miR-203a-3p, miR-891a-5p/miR-205-5p, miR-451a/miR-203a-3p, miR-888-5p/miR-203a-3p, miR-888-5p/miR-205-5p, miR-205-5p/miR-144-5p, miR-891a-5p/miR-203a-3p, miR-124-3p/miR-203a-3p, miR-214-3p/miR-144-5p, miR-451a/miR-205-5p, miR-144-3p/miR-205-5p, miR-144-5p/ miR-203a-3p。每个组合均会出现miR-205-5p、miR-203a-3p或miR-214-3p中的一个, 主要原因是这三种miRNA在外周血和月经血中的表达量存在较大的差异(图1C), 在区分外周血和月经血的过程中起到主要作用, 另外一种miRNA起到辅助作用, 主要表现在能够使一种体液中的离群值远离另一种体液。
为进一步选出最优模型, 对测试数据进行不同程度的数据扰动以进行模型稳健性测试, 在每种程度的扰动下分别对上述13个组合重复测试100次, 观察模型的F1值随着扰动程度的增加而发生的变化, 以此来反映模型的稳健性。测试结果显示包含两种miRNA的最佳组合为miR-144-5p/miR-203a-3p, 其次为miR-144-5p/miR-205-5p。对同一组合不同方法构建的模型进行对比发现, 最优方法为核密度估计或逻辑回归, 方法呈现出更好的稳健性。相关结果见图3。
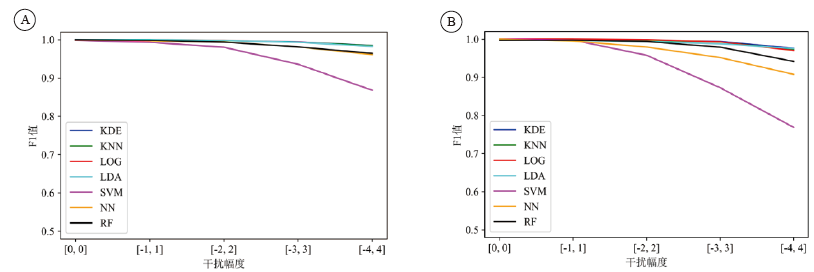 | 图3 两种miRNA组合的不同模型抗干扰效果比较(A:miR-144-5p/miR-203a-3p组合; B:miR-144-5p/miR-205-5p组合)Fig.3 Effect of anti-interference from different models of two miRNA combinations (A: models combined with miR-144-5p and miR-203a-3p; B: models combined with miR-144-5p and miR-205-5p) |
测试miR-205-5p、miR-203a-3p、miR-214-3p两两组合后, 再与miR-144-5p组合, 筛选使用3种miRNA分子标记进行区分鉴定的最优模型, 最终发现选取miR-205-5p、miR-203a-3p、miR-214-3p中的两种或一种与miR-144-5p组合能够得到较好的分类模型, 其中3种标记分子的最优组合为miR-205-5p/miR-203a-3p/miR-144-5p, 两种标记分子的最优组合为miR-144-5p/miR-203a-3p或miR-144-5p/miR-205-5p, 3种标记分子的最优组合比只用两种miRNA的最优模型稳健性更强, 且最优方法为核密度估计方法, 其次为逻辑回归方法。相关结果见图4。
 | 图4 三种miRNA组合的月经血外周血区分效果及其不同模型抗干扰效果比较(A:使用miR-205-5p/miR-203a-3p/miR-144-5p三种miRNA组合进行月经血外周血区分的降维效果图; B:miR-205-5p/miR-203a-3p/miR-144-5p组合的不同模型抗干扰情况对比图)Fig.4 Effects of both differentiation into menstrual and peripheral blood with three miRNA combinations and anti-interference from different models (A: the dimension-reduction-related discrimination between menstrual and peripheral blood with three miRNA combinations of miR-205-5p, miR-203a-3p and miR-144-5p; B: anti-interference effects of different models performed with the combination of miR-205-5p, miR-203a-3p and miR-144-5p) |
根据上述数据模型分析结果, 最终分别采用逻辑回归、核密度估计两种方法训练判别模型进行软件开发。该软件的模块包括模型选取、特征项输入、鉴定结果三个部分。运用数值模拟原理结合判别分析模型, 输入待鉴定体液中测定的miRNA相对表达量数值, 即可得出软件判别模型的预测结果, 从而准确快速地检测出未知血液样本的类型。
该软件内置了三种最优特征项组合(最优特征项组合一:miR-144-5p/miR-203a-3p/miR-205-5p; 最优特征项组合二:miR-144-5p/miR-203a-3p; 最优特征项组合三:miR-144-5p/miR-205-5p), 用户也可自定义特征项组合。
当验证少量样本时, 用户可在特征输入面板输入对应的特征项数值。输入完成并检查无误后, 点击“ 类型鉴定” 按钮, 即可在鉴定结果面板输入鉴定结果信息。当验证大量样本时, 用户需要批量导入训练数据, 导入完成后选取最优特征项组合, 点击模型训练进行体液类型的鉴定分析。
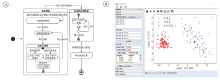
本软件状态流程图见图5A所示。
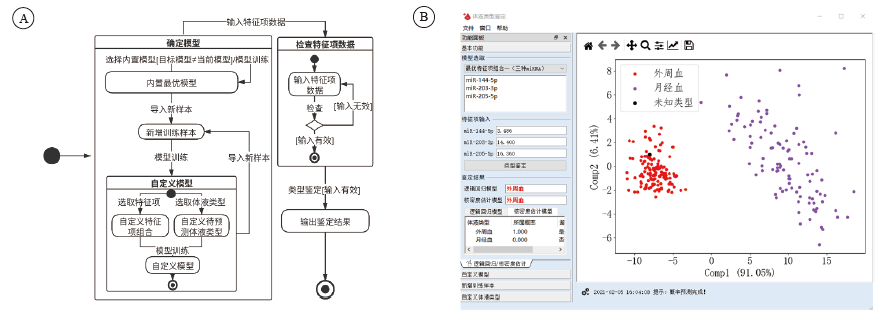 | 图5 体液类型鉴定软件状态流程图(A)及软件运行示例(B)Fig.5 Operational flowchart of humoral-type-identifying software status (A) and exampling result from the software performing (B) |
使用SYBR Green荧光定量PCR检测方法, 检测获取未知样本中miR-144-5p, miR-203a-3p, miR-205-5p等3种miRNA的相对表达量数据。从基本功能模块中的模型选取面板选取“ 最优特征项组合一” , 在特征项输入面板中输入未知样本中以上3种miRNA的相对表达量数据值, 点击“ 类型鉴定” 按钮后, 在鉴定结果面板输出两种数据分析方法所分别给出的判别结果, 未知样本两种判别方法均为外周血, 同时给出判定的概率数值:属于外周血的概率为1, 属于月经血的概率为0。
同时在右侧的图形化展示面板中, 直观展示未知样本的分布情况。图形化展示面板是通过降维分析展示的两类体液的样本数据分布差异, 其中外周血为红色实心圆点集合、月经血为紫色实心圆点集合, 未知样本(黑色实心圆点)落在外周血样本组成的数据集内, 见图5B。多个实际样本测试结果显示, “ 最优特征项组合一” 对外周血和月经血的区分度最好。
本研究基于文献报道选择了十种在常见体液中具有特异性表达能力的miRNA和七种数据分类方法, 并检测了这些miRNA在240份血液样本(外周血136份, 月经血104份)中的相对表达量并作为训练集用于数据分析, 以探索最佳的外周血和月经血分类模型。这十种miRNA标记分子在两种血样中差别最大的三种miRNA分别是miR-205-5p、miR-203a-3p和miR-214-3p, 最终选择并推荐使用的用于区分两种血液的最优组合为miR-205-5p/miR-203a-3p/miR-144-5p。其中, miR-203a-3p和miR-205-5p是上皮细胞的特异性microRNA[21, 22], 而miR-214-3p在宫颈组织中高表达[23], miR-144-5p在月经血中特异性过表达[14], 其生物学功能与数据分析结果一致。同时, 经对七种分类方法的详细分析, 发现核密度估计和逻辑回归是最适合解决此问题的方法模型。核密度估计分类算法为无监督机器学习算法, 能够从样本数据本身学习而辨识其分布特征, 无需事先假设样本数据符合某种特定分布。因此, 在样本数据的数量和质量均较高的前提下, 核密度估计分类算法理论上能够更好地反映出样本的实际分布特征。逻辑回归判别模型为线性分类模型, 并采用sigmoid函数进行了非线性映射, 使得远离分类决定面的数据作用减弱, 对数据集中噪声的鲁棒性很好。
研究最终基于核密度估计和逻辑回归开发了自动化判别软件。使用时, 首先选取特定的miRNA组合, 训练得到核密度估计判别模型和逻辑回归判别模型, 之后在对未知样本进行判定时, 输入待鉴定体液中测定的对应miRNA的相对表达量数值, 最终就可得到核密度估计和逻辑回归两种判别模型的预测结果。软件内设的三组最优组合均能明显地将外周血和月经血区分开, 在实际应用时可根据检材条件进行相应的组合选择, 在检材足够的条件下, 推荐优先使用最优特征项组合一。
针对外周血和月经血混合检材的判定问题, 对一部分模拟样本也进行了验证, 区分效果良好。但考虑到月经血本身的特性, 以及个体差异性等因素, 仍需进一步进行较大数量的数据验证, 以得出更可靠的结果。同时相应数据可进一步输入软件, 扩充训练集样本规模, 以进一步优化和提高软件自身的判别分析性能。
本研究探索了鉴别外周血和月经血的miRNA标记组合, 发展了鉴别算法和自动判别软件, 测试结果准确, 所开发的自动判别软件界面友好、使用简单, 适合辅助法医实践关于外周血和月经血的判别分析中的计算工作, 可有效服务于法医物证工作, 有较大的推广应用价值。在样本量足够的前提下, 软件优先推荐使用“ 最优特征项组合一” 并选择核密度估计模型或逻辑回归模型进行未知血液样本的类型判定。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|