


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度卷积神经网络的语音降噪研究
[张琨瑶 , 王华朋, 牛瑾琳, 倪令格, 刘元周]
, 王华朋, 牛瑾琳, 倪令格, 刘元周]
, 王华朋, 牛瑾琳, 倪令格, 刘元周]
|
|


第一作者简介:张琨瑶,女,河南郑州人,硕士研究生,研究方向为声像资料检验。E-mail: 15038229006@126.com
目的 为了提高实际工作中获取到的音频资料中语音的质量,降低噪声对语音质量及可懂度的影响,提出了一种基于深度卷积神经网络的语音降噪模型。方法 该模型通过卷积、加偏置、批量归一化、Relu激活的多层循环结构,能够有效地对低信噪比条件下语音中的洗衣机噪声、鼓掌噪声、汽车内部噪声等多种常见的环境噪声进行降噪处理。结果 最终含噪语音经过模型处理后的MOS评分达到3.91分,其中最高分4.05分,最低分3.81分。结论 该模型能够切实提高含噪语音的质量及可懂度,对于实际的公安工作、智慧警务建设、语音分析、语音文本识别等具有重要的意义和价值。
Objective Speech, one of the main means for people to communicate, is definitely capable of providing reliable clues for relevant cases to solve and powerful evidence for trial. However, the forensic-purposed speech materials are usually prone to high probability of containing environmental noise that affects the quality of the speech. Thus, a model of vocal noise reduction was here to put forward based on deep convolutional neural network so as to debase the influence of noise on speech quality and intelligibility.Methods A model of multi-layer cycling structure was set up through the procedural operation of 2D convolution, bias addition, batch normalization and Relu activation. With optimizing repetitions of the structure, such a model of deep convolutional network was drilled to denoise a variety of common environmental noises (e.g., those from washing machine, clapping and inside automobile) that were contained with speech of low SNR (signal-to-noise ratio). Adam algorithm was used to optimize the training parameters for network to drill. The assessment methodology was adopted with that developed by the Telecommunication Standardization Unit of the International Telecommunication Union (ITU) for evaluation of voice/video quality.Results For the noise-containing speech signals processed through such the setting-up model, the MOS (mean opinion score) was up to 3.91 scores, with the highest 4.05 and lowest 3.81.Conclusions The model set up here is of strong generalization ability to tackle various environmental noises, capable of effectively improving the quality and intelligibility of noisy speech, therefore potential for the involving speech analysis and speech text recognition to play roles into public security practice and construction of intelligent policing.
语音作为一种携带言语信息的声波, 是人类接收、传播信息的主要媒介之一。在实际的公安工作中, 一方面, 语音可以真实记录侦查过程中犯罪嫌疑人的言语内容及语音特征, 反映某些案件事实以及说话人的情绪、心理状况等, 为破案提供可靠线索, 为审判提供有力证据; 另一方面, 它所记录的内容, 能够维护犯罪嫌疑人的合法权益, 对办案人员的执法行为进行有效监督。语音携带重要的有用信息, 但也会受环境、记录设备、传输设备等因素的影响, 产生一些影响其质量及可理解性的噪声。为了准确记录犯罪嫌疑人的言语信息、查明犯罪事实、保证公安人员执法权的合理行使, 使各项工作顺利进行, 通常需要对含噪语音进行降噪处理, 以提高语音的质量及可理解性。
目前, 国内外有多个团队、多位学者在进行语音降噪的相关研究。根据是否建立模型, 目前应用的算法大致分为两种类型:模型算法、非模型算法。其中, 非模型算法因为不需要从含噪信号中估计模型参数, 使用过程更加简便, 应用范围也相对更广, 但是由于没有利用真实语音的统计信息, 因此结果一般不是最优, 这类方法包括谱减法、盲源分离法等。模型算法又分为参数方法及统计方法。典型的参数方法有各种滤波器、人工神经网络、子空间等, 这类方法首先要建立一个语音模型或噪声模型, 提取出模型参数, 在此基础上进行去噪。模型类算法中的统计方法是利用语音及噪声的统计学特征, 在建立好的模型数据库中, 通过训练获得初始统计参数, 加强语音特性、减弱噪声特性实现语音增强。Ephraim等[1]提出了一种基于协方差矩阵特征值分解的方法, 利用卡-罗氏转换(Karhunen-Loeve transfrom, KLT)进行信号分解, 实现了噪声值低于阈值约束, 并且语音失真程度最小化; Faraji和Kohansal[2]推导出加性高斯噪声中语音增强的最小均方误差(minimum mean square error, MMSE)和最大后验(maximum a posteriori, MAP)估计的闭合形式解, 在实现语音增强目的的同时, 使得增强信号的失真最小化。当然, 模型算法与非模型算法并非相互独立, 对于不同的场景, 可借助不同算法或网络的优势, 或将两者结合起来, 共同实现语音增强的目的。
俄亥俄州立大学计算机科学与工程系的汪德良教授及其团队, 自21世纪初期开始从事语音增强方法的研究[3], 以音源分离为切入点, 致力于解决语音增强领域著名的“ 鸡尾酒会问题” , 首次将深度学习应用于语音增强领域。目前, 能够应用到语音增强领域的神经网络结构很多, 除了循环神经网络、卷积神经网络、带有门控循环单元的神经网络、生成对抗网络等基线网络外, 它们的变体也能够应用于语音增强领域。2019年Abouzid等[4]提出了卷积去噪自动编码器(convolutional denoising autoencoders, CDAEs)的一种谱矩阵, 用于在嘈杂语音中抑制噪声, 以达到语音增强的目的; 高登峰等[5]在基于全卷积神经网络的基础上, 联合跳跃连接结构及次要特征进行学习, 实现了空管对话环境中良好的语音增强表现; Tan和Wang[6]提出了一种用于复杂谱映射的门控卷积递归网络(GCRN), 有效提高了语音的幅度和相位响应; Zhao等[7]提出了一个基于深度神经网络(deep neural network, DNN)的两阶段框架来增强杂波语音, 另外将净语音相位纳入目标函数来执行系统优化, 以获得更好的幅度谱估计。
考虑到在实际公安工作中, 获取的语音会出现环境噪声概率大、影响语音质量的情况, 本文提出了一种基于卷积神经网络的语音增强方法。实验结果表明, 该方法对于多种环境噪声具有较强的泛化能力, 应用于已知环境噪声种类的情况下, 能够有效提高语音质量及可懂度, 降低环境噪声对语音内容清晰度的影响。
假设语音信号为x(n), 在噪声信号中随机取一段噪声片段h(n), 含噪语音信号y(n)即为:
x(n)+ h(n)=y(n) (1)
为分析语音随时间的变化, 根据语音的短时平稳性, 将得到的净语音x(n)、含噪语音y(n)分别进行分帧、加窗处理, 得到信号的连续性变化; 为避免使用窗函数处理后语音信号丢失的情况, 设置窗之间的重叠部分, 使窗的滑动步长小于窗长[8]。在本次实验中为了获得语音信号的周期性变化, 防止突然截断导致的频谱泄露, 使用海明窗(Hamming)。窗函数为:
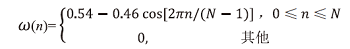
随后对预处理后的y(n)做短时傅里叶变换(short-time Fourier transform, STFT), 获得STFT向量:
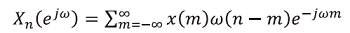
若令 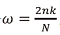
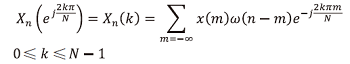
1.2.1 卷积神经网络的搭建
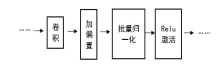
考虑到全连接神经网络参数庞大的问题, 采用全卷积神经网络代替, 相比于其他网络, 卷积神经网络能够更加准确地获取语音信号的局部特征, 将其运用在语音降噪中, 能够更好地恢复出语音信号的主要成分。实验中使用的深度卷积神经网络包含17个2D卷积层、部分批量归一化层(batch normalization)、Relu激活层、回归层。中间的15个卷积层分为3组, 重复6次。2D卷积层在输入中应用滑动过滤器, 卷积层沿输入的垂直、水平方向移动, 计算权重与输入的点积, 然后添加一个偏置项。本实验所采用的卷积神经网络结构搭建示意图如图1。
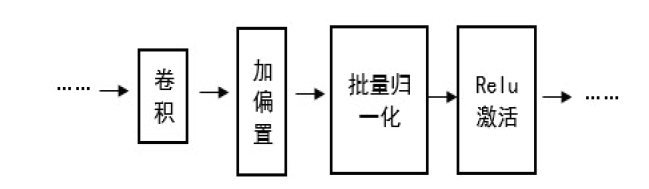 | 图1 网络结构搭建示意图Fig.1 Schematic of the network structure |
在卷积操作中, 以same设置padding参数, 该操作可保持经过卷积层的量前后大小不变。设置批量归一化层使得每次卷积过后, 数据分布趋于一致, 从而提高深层网络模型训练的效率及稳定性。四种卷积层的参数设定如表1。
| 表1 卷积层的参数设定 Table 1 Parameter setting for the convolutional layers |
1.2.2 网络训练参数优化
Adam(adaptive moment estimation)算法是由Open-AI的Kingma和多伦多大学的Ba于2015年在ICLR论文中提出的一种一阶优化算法, 它能够替代传统的随机梯度下降算法(stochastic gradient descent, SGD), 由此基于训练数据迭代来实现神经网络权重参数的更新。这是因为SGD在网络训练过程中总是保持单一学习率更新所有的权重, 学习率在训练过程中并不会改变。而Adam通过计算梯度的一阶矩估计和二阶矩估计为不同的参数设计独立的自适应性学习率, 兼具适应性梯度算法(AdaGrad)和均方根传播算法(RMSProp)的优点, 加快函数收敛的速度, 完成噪声模型的预测, 实现较好的语音降噪效果。
1.3.1 均方根误差
均方根误差(root mean squared error, RMSE)亦称标准误差, 是预测值与真实值偏差的平方与观测次数n比值的平方根, 即均方误差(mean square error, MSE)的平方根。
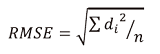
其中, di是预测值与真实值的偏差, 即di=y(i)-ŷ(i), n表示观测次数。
该指标能够体现降噪过后的语音与原始净语音的偏差, 以此衡量该模型的降噪效果。在本实验中, 该模型在训练阶段使用均方根误差作为衡量模型训练效果的依据, 将模型训练至均方根误差最小的状态, 也认为此时模型参数为最优, 能够达到最好的降噪效果。
1.3.2 MOS评分
MOS(mean opinion score)评分也即平均意见得分, 是由国际电信联盟(International Telecommunication Union, 以下简称ITU)电信标准化部门制定的用于对话音/视频质量进行评价的评估方法。值得注意的是, 在话音业务中要求受试者提供质量评估的过程一样可以轻松地应用于视频和一般音频业务, 还可以要求受试者评价业务的整体视听质量。除了话音应用, ITU针对视频和一般音频制定了不同的标准来描述主观测试的不同方面[9]。
在测试中进行评价时, 最常用的评分量表是5点绝对等级评定的ACR量表, ACR量表是离散量表, 也即单个受试者对于话音或者音频信号质量的评价只能由1、2、3、4、5这五个数字表示。在本文的实验中, 为避免离散化ACR量表的局限性, 规定受试者可以采用0~5之间的小数(保留一位)来对降噪后的语音进行打分, 以此来消除5点绝对等级评定只能用整数值来评价的局限性。
在实验设计中, 话音或视频的持续时间一般要在6~10 s, 这种限定为受试者提供了足够的评价时间, 并且不会引入过多的偏差, 此外, 为了减少性别因素带来的偏差, 要求受试者的性别子条件平均, 这种设置方式使得MOS评价的结果更具可信性及可借鉴性。
本实验大致分为语音样本的收集、语音预处理、语音特征提取、基于卷积神经网络的模型训练及验证、测试几个部分。实验的基础环境为Ubuntu18.04.3LTS系统以及Windows 10系统, 使用MATLAB2019b平台进行实验。
本实验共采用三个开源数据库, 包括:由Mozilla发布的Common Voice数据库, 该开源语音识别数据集覆盖了18种不同的语言, 包括大约42 000人的1 400 h的语音, 目前仍然在持续更新[10]; ESC-50 数据库[11]包括50 个语义类, 每类有40个示例, 共计2 000段环境录音, 每段录音时长为5 s; NoiseX-92数据库包含了英国荷兰感知研究所(Institute for Perception-TNO)的语音研究单位(Speech Research Unit, SRU)在2589-SAM(1990年2月)项目下实地测量的不同噪声数据, 共包含15种噪声, 每种噪声的持续时间都是235 s[12]。
语音样本的收集分为两部分:1)在训练阶段, 净语音采用Common Voice数据库中的21 000条英文语音, 语音时长及说话人的性别、年龄不固定, 以排除模型对特定年龄或性别的语音过拟合的情况。噪声使用ESC 50 数据库中的洗衣机噪声、鼓掌噪声以及NoiseX-92噪声库中的汽车内部噪声, 共计三种噪声。2)在测试阶段, 净语音包括10名男性的133条语音以及7名女性的67条语音, 共计200条中文语音, 语音内容不限, 发音人的年龄多在20~30岁。噪声语音取自ESC 50中的洗衣机噪声、鼓掌噪声以及NoiseX-92噪声库中汽车内部噪声三种噪声。
本次实验分为训练和测试两部分。为研究低信噪比条件下模型的降噪效果, 将噪声以0 dB的信噪比叠加到纯净语音中, 得到带噪语音信号。训练阶段采用的客观验证标准分别是均方根误差(RMSE), 以及模型损失(Loss)。
训练阶段用STFT从训练中获得目标(净语音)和预测(去噪语音)的振幅向量。定义系统参数时, 窗函数采用汉明窗, 窗长为256, 窗之间的重叠部分为窗长的75%, 即窗的滑动步长为64, 在处理过程中为减小网络运算量, 使用一个采样率转换器, 将语音信号降采样到8 kHz, 通过MATLAB的内置函数randi函数产生随机数, 使用随机数在噪声向量中随机创建一段噪声片段, 以0 dB信噪比将噪声添加到净语音中。在对净语音及含噪信号做短时傅里叶变换后, 对结果取绝对值以去除与负频率相关的频率样本, 减小网络的计算量。从带噪信号STFT中获得8个片段的训练预测信号, 相邻连续的预测器之间的重叠部分为7个片段。测试阶段通过与训练阶段类似的方法获得带噪语音信号, 通过训练段的均值和标准误差来测量输出并用带噪语音信号的STFT向量相位来重建时间域信号。本次实验随机抽取降噪测试集中的11条语音, 由10个人进行打分, 受试者由5名男性及5名女性组成, 受试者年龄在20~40岁之间, 要求在安静环境中(低于35 dB)使用设备中等音量听音, 借助MOS评价体系依次对测试语音进行评分。
通过前期的调试, 本次实验网络在训练时的基本参数如下:InitiaLearnRate(初始学习率)设置为0.000 01; Learn Rate Drop Factor(学习率增长因子)设置为0.9; Learn Rate Period(学习率增长周期)设置为1; Validation Frequency(验证频率)设置为训练预测的第四维大小与最小批量数的比值向下取整; miniBatchSize(最小训练批量的大小)设置为128; Epoch(训练周期)设置为6、20、40。
3.1.1 洗衣机噪声
图2a显示的是对于洗衣机噪声经过20个周期的卷积神经网络训练过程, 图2b显示的是经过卷积神经网络后对带有洗衣机噪声的语音的降噪效果。
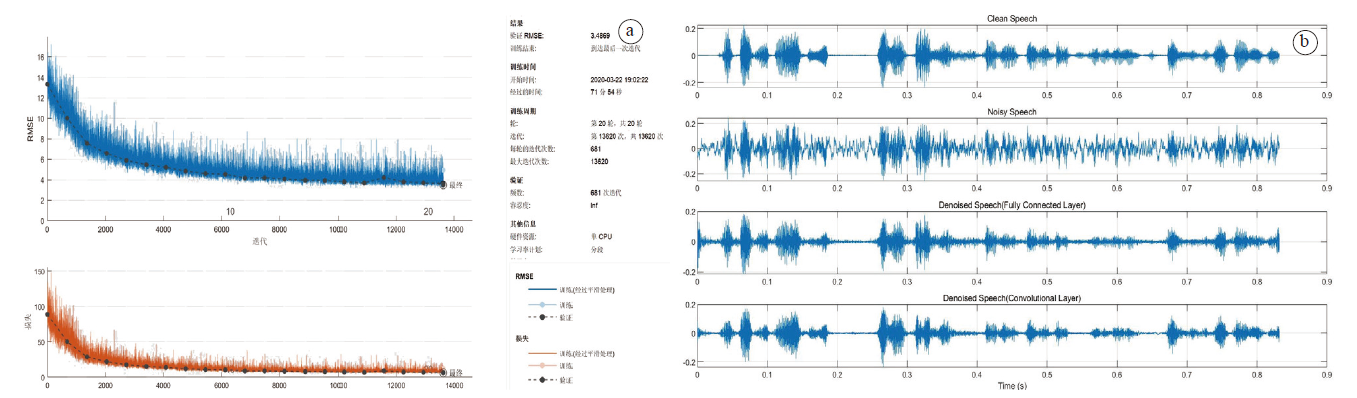 | 图2 深度卷积神经网络对洗衣机噪声降噪的训练过程(a)和效果(b)Fig.2 The training process (a) and effect (b) of deep convolutional neural network to denoise the washing machine noise |
由图2a可以看出, RMSE在训练的前三个周期的变化率较大, 这是由于初始的学习率较低, 而学习率增长因子较大, 因此真实值与预测值偏差的变化在训练刚开始时最大, 随着训练的进行, 真实值与预测值的偏差及其变化逐渐变小, 经过20个周期的训练, 最终RMSE为3.486 9。由图2b可以看出经过卷积神经网络降噪后的语音的一些细节特征得到了较完整的保留, 但还是出现了语音降噪过程中不可避免的语音失真的情况, 但这种程度的失真并不会影响语音的质量以及可懂度。
3.1.2 鼓掌噪声
图3a显示的是对于鼓掌噪声经过20个周期的卷积神经网络训练过程, 图3b显示的是经过卷积神经网络后对带有鼓掌噪声的语音的降噪效果。
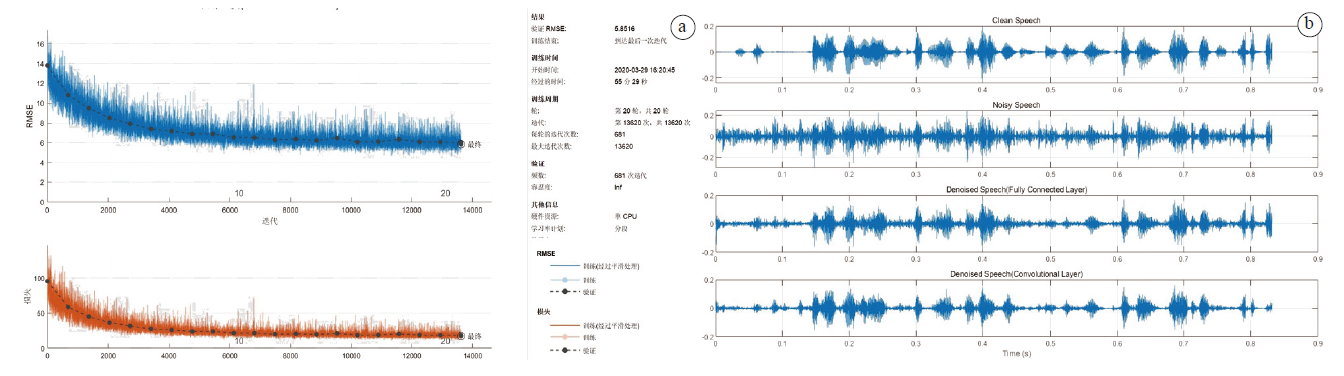 | 图3 深度卷积神经网络对鼓掌噪声降噪的训练过程(a)和效果(b)Fig.3 The training process (a) and effect t(b) of deep convolutional neural network to denoise the clapping noise |
从图3a可以看出, 经过20个周期的训练, 最终RMSE为5.851 6, 该模型对鼓掌噪声的降噪效果不理想, 从降噪效果的图谱来看, 在一些细节的地方造成了语音的失真, 在这种情况下语音的质量及可懂度都一般, 一方面, 这可能与鼓掌噪声本身的片段质量不高或存在其他噪声有关, 另一方面, 可能是由于鼓掌噪声本身会引起空间混响增强, 相比于其他噪声来说不易去除。
3.1.3 汽车内部噪声
图4a显示的是对于汽车内部噪声经过20个周期的卷积神经网络训练过程, 图4b显示的是经过卷积神经网络后对带有汽车内部噪声的语音的降噪效果。
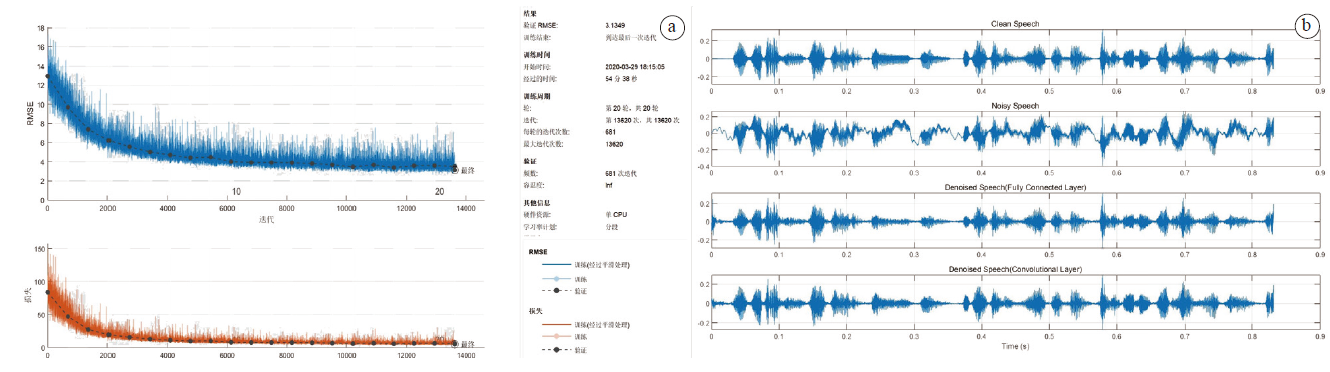 | 图4 深度卷积神经网络对汽车内部噪声降噪的训练过程(a)和效果(b)Fig.4 The training process (a) and effect (b) of deep convolutional neural network to denoise the noise inside automobile |
由图4a可以看出, 经过20个周期的训练, 最终RMSE为3.134 9, 该模型对含有汽车内部噪声语音的降噪效果比较好, 并且在训练周期相同的情况下, 训练的时间相对较短。
本次实验针对不同类型噪声的训练周期以及相应的RMSE、训练时长如表2。根据表中信息可知, 该网络结构对于不同的噪声具有不同的泛化能力。
| 表2 不同类型噪声在训练中的均方根误差及训练时长 Table 2 RMSE and training duration for type-different noises to undergo training |
对语音增强的效果进行评价的方式有多种, 大致可以分为主观评价方法及客观评价方法, 本文主要采用基于MOS的方法, 对降噪语音效果进行主观评价。这种方法是指由不同的人分别对原始语料和经过系统处理后有衰退的语料进行主观感觉对比, 得出MOS评分, 最后求取平均值, 这是一种比较纯粹的主观定性分析。评分细则如表3。
| 表3 对降噪语音的MOS评分细则 Table 3 The grading rules of MOS for denosing |
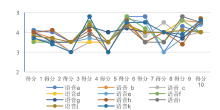
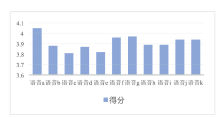
本次实验随机抽取对洗衣机噪声降噪测试集中的11条语音, 由10个人进行打分。每个人对每条语音的打分情况如图5所示, 由于打分均无雷同或对所有语音打分一致的情况, 因此该主观评价过程具有有效性及可信性。每个人对11条语音的MOS评分在3.65以上。如图6所示, 每条降噪语音的MOS评分均在3.8以上, 说明该模型对于语音中的洗衣机噪声的降噪具有可行性, 并且所有语音的总体MOS平均分达到3.91, 说明该模型对于洗衣机噪声的降噪效果较好, 具有实际的应用价值。
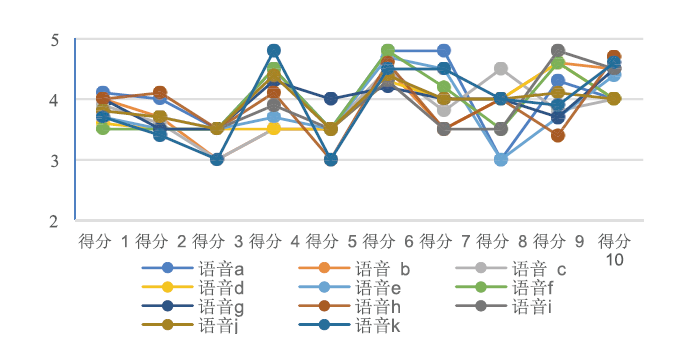 | 图5 10个人对每条语音的评分Fig.5 Score of each selected speech evaluated from ten people |
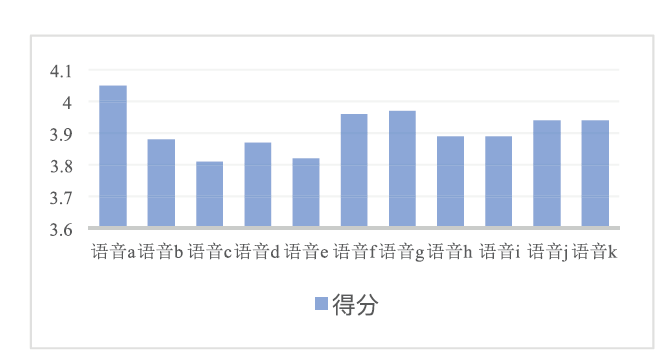 | 图6 每条语音的MOS评分Fig.6 MOS score of each speech |
本研究提出了一种基于深度卷积神经网络的语音降噪模型, 该模型具有卷积、加偏置、批量归一化、Relu激活的多层循环结构, 采用Adam算法对训练过程进行优化, 通过均方根误差锁定局部最优训练周期, 在测试中采用国际公认的MOS评价体系, 对降噪后语音的质量及可懂度进行主观评价, 经过10个人对11段随机语音的主观评价, 每条语音的MOS评分均在3.8以上, 模型的整体MOS评分为3.91。实验结果表明, 这种基于深度卷积神经网络的降噪模型借助Adam算法以及特定的卷积层设置, 能有效降低洗衣机噪声、鼓掌噪声以及汽车内部噪声等常见环境噪声对语音质量及可懂度的影响, 该模型能够满足实际工作中对语音清晰度的要求, 一方面为侦查破案提供更加清晰的语音类证据、线索, 另一方面为后续的语音文本识别、语音分析提供可靠的前端降噪处理。但是, 由于经过语音增强这一处理的语音普遍会出现失真情况, 对于说话人识别这类需要依据语音细微特征来对语音进行分类的操作来说, 这种失真并不利于结果的呈现, 因此如何改善甚至避免语音增强过程中语音失真问题带来的影响, 也正是今后的研究需要解决的。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|