
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
方言识别网络模型的声学信息表征研究
[申小虎1  , 金恬
, 金恬2 , 李佳蔚1 , 韩春润1 ]
, 金恬|
|


第一作者简介:申小虎,男,江苏南京人,硕士,高级实验师,研究方向为人工智能与公安视听技术。E-mail: shenxiaohu@jspi.cn
目的 研究语音识别网络模型在声学信息中的表征能力,并对方言自动分类应用进行最优单模型筛选。方法 使用python仿真实现SOM、RNN、LSTM与CNN模型,并选择合适的分类器进行方言分类任务的训练与分类验证实验。结果 实验结果显示,多分类评价指标PRF条件下,LSTM模型取得了宏平均和微平均的最优评价得分。同时CNN模型则在低信噪比条件下显示了较好的抗噪鲁棒性。结论 LSTM+CNN框架下方言信息表征能力较好且兼具强鲁棒性,可满足方言自动分类任务的二次开发应用。
Objective To explore the presentation of acoustic characteristics with network models for dialect identification so as to screen out the optimal singular model for automatic dialect classifier.Methods Four selected typical neural network models for acoustic feature extraction, SOM (self-organizing feature Map), RNN (recurrent neural network), LSTM (long short-term memory network) and CNN (convolutional neural network), were individually simulated through python. With the dataset containing typical dialects (6036 samples of 105 persons’ spoken voices) from 13 cities in Jiangsu province, three aggregates were respectively built up for purpose of training, verification and test at the division ratio of 6:2:2. The test aggregate was then edited into sub-aggregates of 3 and 10 seconds, having each further added of white noise to form the sub-aggregates owning signal-to-noise ratio (SNR) of 3 and 10 dB. Thus, 4 test aggregates were thereby produced, with each containing 1207 samples. The appropriate classifiers were chosen to evaluate the performance of four above-selected models into their operations of training, verification and test. For the dialect identification, every selected network model was verified of its ability to extract features from the test aggregates owning different SNR and duration.Results With the previously-normalized data and network parameters, the confusion matrices of models were obtained from the output data of 4 neural network models processing into 4 test aggregates, having resulted in the Macro-F1 and Micro-F1 scores that are useful and eligible for evaluation of multi-classification problem. The results showed that LSTM and CNN are significantly better of performance than SOM and RNN. SOM is obviously more sensitive to the SNR of test samples, though having poor identification accuracy with the 3dB test aggregate. RNN has the improved accuracy for dialect identification, yet having the insufficient representation ability to key information of long-term samples. LSTM achieves the optimal evaluation scores of 93.1% (Macro-F1)/92.7% (Micro-F1) with 10dB/10s test aggregate, excelling in overcoming the bug of RNN with its characteristic structural unit. CNN is stable of identification accuracy, not easily affected with the length of speech fragments, thereby having better performance in noise-resistibility for substandard recordings. Owning the nonlinear transformation operations of convolution and pooling, CNN model is of good nonlinear expression ability to demonstrate nice fitting performance for information representation in dialect classification although it is incompetent in real-time presentation with the identified material.Conclusions LSTM+CNN framework is of better acoustic characteristics performance and robustness, capable of meeting the further updating development and application of automatic dialect identification. Besides, the audio sample duration and SNR are still the key for a model (singular or coalesced from two or more) to improve its identification accuracy.
方言分类是根据某语音片段判定其说话人所属方言片区的研判方法, 也是刑事技术的重要组成部分[1]。公安机关侦查破案在尚未掌握犯罪嫌疑人身份的情形下, 例如电信诈骗、恐吓骚扰等案件中依据犯罪嫌疑人方言判定其所属籍贯, 可有效缩小侦查范围, 锁定犯罪嫌疑人身份。
方言自动分类方法较凭经验的传统人工辨识方法, 具有耗时短、精度高、客观性强等优势。目前利用基于梅尔频率倒谱系数[2]、线性感知预测系数[3]等底层声学特征的语种识别模型进行语种识别、方言分类等相关研究已趋于完善。文献[4]通过自组织特征映射网络(self-organizing feature map, SOM)对梅尔倒谱系数(Mel-scale frequency cepstral coefficients, MFCC)进行无监督聚类, 并使用支持向量机(support vector machines, SVM)完成了方言辨识分类。文献[5]则基于向量空间模型(vector space model, VSM)对分割后的声学单元进行特征表示并用于模型训练, 最终得到优于标准数据集的分类效果。为克服短时方言识别精度低的问题, 文献[6]利用深度学习方法得到信息表征能力较好的瓶颈特征。近年来经典深度学习模型被广泛应用于语音分类任务中, 其主要贡献是为原始特征提供一种高层特征表示, 以创建一个更容易区分的特征空间, 并认为在经过深度神经网络处理后的特征空间中, 只要运用浅层的softmax分类器就能达到很好的识别效果。针对语音具有时序特征属性, 文献[7]分别使用循环神经网络(recurrent neural network, RNN)与长短期记忆网络(long short-term memory, LSTM)实现了基于区分词的方言分类。同时文献[8]在实验中也发现, 使用底层声学特征会丢失部分特征信息, 因此采用了基于音素序列的学习方法PTN实现语种分类, 并取得优于LSTM的分类精度。文献[9]针对方言分类任务, 通过MatConvNet工具箱构建卷积神经网络(convolutional neural networks, CNN), 利用单音节二维声谱图进行训练验证, 对江苏方言实现了简单分类任务。上述文献的研究成果表明, 寻找合适的深度学习模型框架, 构建基于端到端的方言分类深度声学模型具有一定的可行性与研究价值。
不同网络模型下的声学信息表征是影响方言分类应用识别准确率的重要因素之一。本文将目前常用网络模型结构SOM、RNN、LSTM、CNN分别利用python语言在Tensorflow平台进行实现, 并构建江苏省内方言库用于模型训练、验证与测试。最后进行不同模型间的训练集优化、网络调参、分类性能对比分析实验, 验证方言识别网络模型的声学信息表征能力, 为未来开发建设方言自动判定系统提供研究基础。
在语音识别的声学建模领域, 传统神经网络GMM-HMM模型[10]虽可通过扩帧方式获得长时特征信息, 但扩帧能力有限且不能学习深层非线性特征。随着深度学习网络的兴起, 学者Hinton首先将深度神经网络DNN-HMM应用于语音学科领域[11], 并获得识别性能的显著提升。接着, 为预测长时序列语音数据, 存在自环连接的RNN被提出并成功运用于声学建模上[12], 但该模型由于长时依赖记忆问题易于产生梯度消失、梯度爆炸问题。基于此, 学者Gonzalez等[13]提出建立RNN变体, 即LSTM识别方言, 使识别性能提升了15%以上。而在语音识别领域, LSTM-HMM取代DNN-HMM模型成为最广泛应用的结构。同时, CNN也被成功应用于语音识别与短时语种识别[14, 15]。CNN不同改进模型VGGNet、GoogleNet和ResNet的提出, 都为CNN在方言识别上提供了研究方向。
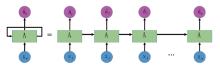
RNN是一种存在“ 内部递归” 的神经网络, 如图1所示。在方言信息表征过程中, DNN需要通过扩帧的方式来表达语音的上下文信息, 窗长一般是固定的, 而RNN可以将上一帧作为辅助与本帧信息一起在网络中学习。
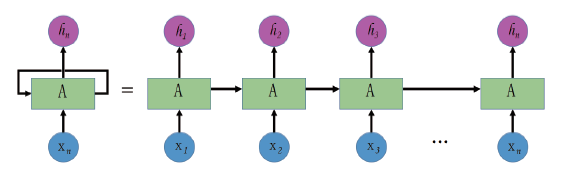 | 图1 RNN网络模型结构Fig.1 RNN network model |
语音信息在流动过程中存在不定向的循环, 确保了网络有选择地存储信息内部状态。由于RNN网络每步存在更新, 因此能够对长时间语音片段进行建模。需要注意的是, 节点数量的增加可以提升模型表达能力, 但是同时也会带来过拟合以及计算效率低下等缺点, 因此选择合适的节点个数也是声学建模的关键点之一。
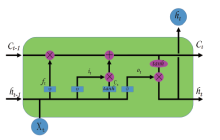
LSTM算法为解决RNN算法在网络训练过程中因收敛问题导致的梯度消失和梯度爆炸增加了状态过滤。如图2所示, 一个完整的LSTM结构可以理解为一个从左到右的信息向量流, 包括在时间步长t处的输入向量Xt、时间步长t-1处之前的隐藏状态向量ht-1和之前记忆单元状态在时间步长t-1处的编码向量Ct-1。与传统的RNN相比, LSTM解耦了隐藏状态ht和存储单元Ct, 使内存容量翻倍, 并允许网络通过创建一个复杂的内存来学习与处理更长时间间隔内的输入信息。
 | 图2 LSTM网络模型结构Fig.2 LSTM network model |
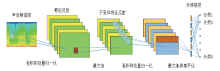
音频的频谱图结构特征能够良好地表征声音场景数据, 并作为深度学习模型的输入。CNN起源于多层感知机网络(multilayer perceptron, MLP), 利用了卷积运算和池化的思想, 通过稀疏连接、权值共享和有选择的时空子抽样处理, 按照输入层、卷积层、池化层、全连通层、输出层的顺序形成模型架构, 如图3所示。
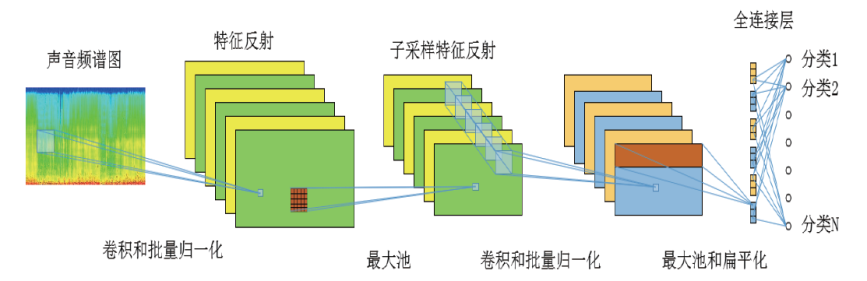 | 图3 CNN网络模型架构Fig.3 CNN network model |
利用卷积在时间空间的平移不变性克服方言信号的多样性是可行的。然而, 目前在方言分类研究领域, CNN架构的基本算法较依赖数据集训练量的大小。
实验首先构建用于训练学习的江苏方言样本库, 接着设计实验方案并建立性能评价标准, 最后通过不同学习网络模型的参数设置并开展性能评价, 挖掘具有方言特征的语音数字信号结构特点, 建立基于深度学习的声学建模方法。
方言库构建采用从已有资源中挖掘符合训练要求的语音语料数据集的方案, 构建江苏省内方言数据集。江苏方言区大致分为江淮官话、吴语与中原官话三个方言区。其中, 中原官话的分布区域大致位于徐州、宿迁北部与连云港北部; 吴语分布区域大致位于苏锡常地区、南通南部、泰州靖江、镇江丹阳; 江淮官话则大致分布于江苏省其余县市区。吴语又可细分为太湖片和宣州片, 在江苏省辖区内主要由太湖片的毗陵小片与苏沪嘉小片组成, 江淮官话可细分为泰如片与洪巢片。目前已有针对全国方言大分区而设计的公开数据集, 但实践过程中发现部分特定地区仍达不到开展深度学习训练所需数据量。同时, 数据集存在标签附着不完整, 细分度不足等问题。基于此, 实验中首先设计由各地区代表性俗语组成的文本, 并对上述方言区内105个说话人按照本地区俗语文本的口述语料进行录音采集。同时将中文方言语音识别数据库(King-ASR-M-004)、《方言江苏• 乡音悠扬》视频资料作为补充语料。所有语料样本均经过降噪、参数规整、静默段切除的预处理, 格式为wav格式, 采样率11 025 Hz, 采样位数16 bit, 时长10 s, 共计得到江苏方言基础语料样本6 036例。同时, 根据说话人所属地区对每例语料样本添加归属地(共5类)标签。
表1为组成采集文本的各地区部分典型俗语, 其中各地俗语采用汉语注音方法(横式)。
| 表1 江苏省各地区部分典型俗语 Table 1 Typical dialects spoken in Jiangsu province |
实验中按照6∶ 2∶ 2的比例切分训练、开发与测试集。对方言测试集进行进一步编辑分类, 通过剪辑形成3 s与10 s的测试集, 再对测试数据集中分别加入白噪声, 形成信噪比分别为3、10 dB的测试集, 从而最终形成共4份测试数据集, 每份测试集中均含1 207份测试样本。
使用建立的江苏方言语料集与构建的各网络模型进行训练、验证与测试。由于建立的网络模型所解决的为闭集多分类问题, 因此准确率不再是唯一的评价指标。考虑到各分类下的样本数相对均衡, 因此本实验同时采用多分类评价指标PRF下不带权重的宏平均Macro-F1和微平均Micro-F1作为各实验模型的评价指标[16]。
该评价指标将多分类问题分解为N个二分类问题, 即产生多个混淆矩阵。每个混淆矩阵中某地区M的方言样本被正确分类到M, 记为真正例TP; 不属于某地区M的方言样本被错误分类到M, 记为假正例FP。属于地区方言M的样本被错误分类为非M地区方言时, 记为假负例FN。
1)Micro-F1标准
Micro-F1是基于微查准率和微查全率的调和平均定义的。计算公式如下:
微查准率:$microP = \frac{\bar{TP}}{\bar{TP}+\bar{FP}}$ (1)
微查全率: $microR = \frac{\bar{TP}}{\bar{TP}+\bar{FN}}$(2)
$micro-F1 = \frac{2× microP × microR}{microP+microR}$ (3)
其中, $\bar{TP}$、$\bar{FP}$、$\bar{FN}$表示各混淆矩阵中对应各数值的算数平均。
2)Macro-F1标准
首先需要根据每个分类的混淆矩阵计算其查准率P和查全率R, 然后计算平均值(不考虑样本权重)获得macroP与macroR, 最后求得Macro-F1。具体公式如下:
宏查准率:$macroP=\frac{1}{n}\sum_{1}^{n} P_{i}$ (4)
宏查全率: $macroR=\frac{1}{n}\sum_{1}^{n} R_{i}$(5)
macro-F1=\frac{2× macroP× macroR}{macroP+macroR} (6)
其中n为样本分类数, 本实验中根据方言区个数n=5。宏平均Macro-F1与微平均Micro-F1的数字反映了模型的稳定性, 其取值范围为[0, 1]。在充分考虑模型泛化能力的前提下, 其数值越大代表模型性能越稳定。
将基于SOM、RNN、LSTM、CNN共4类模型架构, 尝试最优参数设置方案进行训练与验证。
2.3.1 数据规整
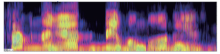
针对SOM、RNN、LSTM模型, 利用kaldi工具包提取MFCC特征, 并选择使用MFCC及其一阶差分、二阶差分系数共36维特征作为网络输入, 采用傅里叶变换帧长为25 ms, 帧移为10 ms, 加窗类型为汉宁窗。为使输入特征满足CNN模型的二维数据格式, 实验中使用python中PIL图像处理库函数对图片进行规整。首先使用specgram函数方法将一维音频数据转换成二维谱图格式, 如图4。接着使用crop函数方法删除时间维度中的空白区域。最后将频谱图中频率维度与时间维度的长度保持一致, 使用resize函数方法规整图片尺寸为224× 224。
 | 图4 特征频谱图Fig.4 Characteristic frequency spectrum |
2.3.2 网络设置
1)SOM模型
实验通过SOM对36维MFCC特征进行聚类, 并选择以结构风险最小化为准则的支持向量机SVM作为分类器。由于SOM-SVM模型不受样本特征维度的影响, 因此可以在小样本空间条件下取得好的分类效果。
经过实验分析, 在SVM分类器核函数选择上, 选择高斯径向基函数作为核函数, 惩罚系数C=150, 训练误差=0.002。
2)RNN\LSTM模型
训练中发现学习速率、隐藏层等超参数设置对模型分类性能会产生较大影响, 因此不断尝试后选择隐藏层层数为3, 此时准确率为最佳状态。实验中同时尝试不断增加隐藏层节点数, 发现当神经元数目达到128时模型训练时间显著增加, 因此神经元数目最终选择设置为256。选择sigmoid激活函数并采用交叉熵损失函数。为平衡收敛速度与迭代次数的关系, 设定batch_size为64, 完成一次epoch需迭代约60次。学习率衰减选用固定步长衰减策略, 通过不断调试设定学习速率初始值为0.05, 每20次epoch降低0.01, 优化器则定义为AdamOptimizer。
在上述参数条件下, 损失函数在训练15次epoch左右时趋向平稳。实验在相应的RNN/LSTM结构基础上通过竞争输出模式, 对各节点所属方言区域进行分类。
3)CNN模型
参考文献[17]的卷积层结构建立实验模型, 该模型由6个卷积层与3个全连接层组成, 仅在第1个卷积层后增加1个池化层, 选择maxout作为激活函数。CNN模型的输入大小为224× 224× 3、选择卷积核尺寸为3× 3, 步长为1, 池化尺寸选择3× 1, 即仅在频域范围进行池化。 padding参数设定为same, 即完成每次卷积后使用零填充(zero-padding)控制特征谱图大小, 模型参数量约为4.1M。经过反复实验, 确认超参数设定为mini-batch=32, 迭代次数epoch=150, 其中前100次迭代学习速度0.05, 后50次迭代学习速率降为0.005。最后全连接层输出通过softmax计算状态后验概率并得到分类结果。
为验证不同数据集样本数量、信噪比与样本时长对方言分类产生的影响, 选择4类神经网络模型对4类测试数据集进行江苏省内方言分类测试, 使用sklearn库函数f1_score计算得到不同数据集下的方言分类混淆矩阵与评价指标Micro-F1值、Macro-F1值。在10 s/10 db数据集条件下的LSTM模型与CNN模型分类混淆矩阵如图5所示。按照公式(1)~(6), 基于得到的混淆矩阵进一步计算可得到不同测试集下各网络模型的评价指标Micro-F1值、Macro-F1值。宏平均Macro-F1数值容易受到测试集中各方言样本数不均衡的影响, 具体如表2所示。
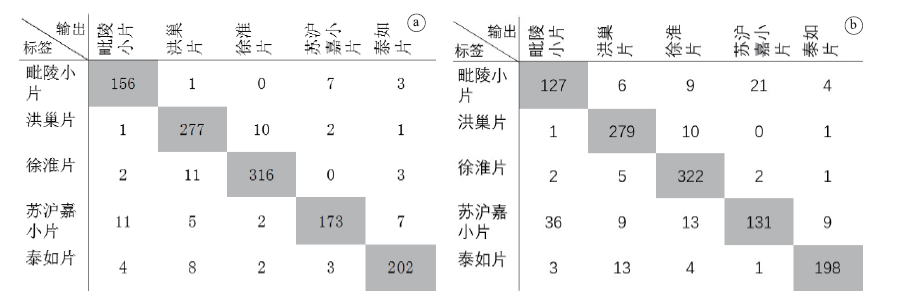 | 图5 10s/10db数据集下的方言分类混淆矩阵 (a. LSTM; b.CNN)Fig.5 Confusion matrices with 10s/10dB dataset for dialect identification (a. LSTM; b. CNN) |
| 表2 不同测试集各网络模型的性能评价 Table 2 Performance evaluation of network models with different test aggregates |
从表2的实验结果中可以看出, LSTM模型获得了最佳评价指标值, 且LSTM与CNN模型的评价指标明显优于SOM与RNN模型。SOM神经网络能够较好地适应本实验数据集条件下的分类, 但SOM神经网络明显对样本信噪比更加敏感, 在3 db测试集下的识别准确性较差。RNN的方言识别准确率得到了一定的提升, 但针对长时语音中时间间隔较长重要信息的表征能力不足。由于LSTM利用自身模型结构单元特点克服了RNN的上述缺点, 因此在10 s测试集下得到了最佳评价指标值。
CNN模型的识别准确率较稳定, 不易受到语音片段长度的影响, 且对语音噪声干扰具有较强的鲁棒性。这是由于CNN模型中的卷积、池化等非线性变换操作具有更好的非线性表达, 对方言分类应用的信息表征具有较好的拟合能力, 但需要注意的是CNN在识别速度上不能满足实时性的要求。
实验结果显示, 在抗噪性能上, 各实验所用网络模型在不同信噪比的数据集条件下得到的评价指标 Micro-F1值、Macro-F1值与信噪比数值均呈现正相关。同时, 数据样本时长也与评价指标值存在正相关关系。这表明各网络模型在短时语音信息提取、提升抗噪鲁棒性上取得了一定的进步, 但语音样本的时长与信噪比仍然是影响模型分类精度的重要因素之一。
利用深度学习框架解决方言自动识别任务是未来的重要研究方向, 本文研究了SOM、RNN、LSTM、CNN网络模型下的声学建模实现与信息表征分析。通过实验结果的分析比较, 论证了CNN、LSTM网络模型均具有方言声学信息的良好表征, 且CNN抗噪能力较强, 展示了CNN与LSTM的联合应用在未来进行方言自动分类二次开发具有一定的可行性。同时实验结果也揭示了标准声纹库建设需建立规范的声纹样本采集标准, 可为声纹识别技术在公安实战中发挥战斗力提供重要保证。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|