
{kind=link}
{kind=link}
基于语音情感分析系统的语音压力测谎
[晁亚东 , 王华朋
, 王华朋* , 刘恩, 倪令格, 刘元周]
, 王华朋, 刘恩, 倪令格, 刘元周]
|
|


第一作者简介:晁亚东,男,山东菏泽人,硕士在读,研究方向为法庭说话人识别。E-mail:515531332@qq.com
目的 探究语音情感分析系统(Layered Voice Analysis,LVA)在不同情况下的表现,并通过分析数据找出影响系统识别率的因素。方法 设置两种不同场景对20名研究对象进行提问,并录音。通过LVA语音系统对语音样本进行分析,使用SPSS统计软件对系统生成的参数进行统计分析。结果 在未告知研究对象实验真相的情况下LVA语音系统平均识别率为91.75%,要远高于研究对象在知情情况下的识别率。在询问过程中,当未涉及敏感问题时,随着时间的推移研究对象的心理压力逐渐减小。结论 LVA语音系统具有良好的情感分析和识别能力,可为司法工作提供参考。
Objective To explore the performance of LVA (layered Voice Analysis) system in different situations so as to find out the factors that affect the recognition rate of the system by analyzing the collected phonetic data.Methods Twenty subjects were asked with questions under two different scenarios, having their answering voices recorded. The recorded speech samples were detected by LVA system so that thus-generated parameters were analyzed by SPSS statistical software.Results The average recognition rate of LVA system was 91.75% when the subjects were not informed of the truth of experiment, contrasting against the comparatively lower recognition rate while the subjects were informed. When being questioned, the subjects were gradually decreasing their psychological pressure with time elapsing if no sensitive questions were involved.Conclusions LVA speech system is well able to use into emotion analysis and recognition, capable of providing reference for judicial work.
语音是人与人日常交际中的主要载体, 其中不单单只是文本信息, 还包含着丰富的情感信息[1]。早在上世纪七十年代, 国外的科学家已经开始研究语音情感, 威廉姆斯发现人的情感在变化时对语音的基音轮廓有非常大的影响, 这是国外最早的语音情感方面的研究之一。到了八十年代中期, 科学家尝试对语音情感进行分类。随着信息技术的高速发展, 人类对计算机的依赖不断增强, 利用多媒体计算机系统研究情感信息越来越受到研究者的重视, 分析情感特征、判断和模拟说话人的喜怒哀乐成为一个意义重大的研究课题[2, 3]。1990年, 麻省理工大学多媒体实验室构造了一个“ 情感编辑器” 对外界各种情感信号进行采样[4], 如人体的生理信号、脸部表情信号、语音信号来识别各种情感。在本世纪初期, 国内各大高校纷纷开始进行语音情感分析与识别方面的研究, 北京科技大学信息工程学院提出基于BDI Agent技术的情感机器人语音识别技术研究方法[5-6]。
人工智能的发展为研究语音情感带来了新手段[7, 8, 9]。在司法工作中, 侦查人员要对犯罪嫌疑人进行审讯, 只通过简单的对话交流侦查人员往往很难判断犯罪嫌疑人所陈述内容的真伪。LVA语音系统是以色列国防部采用“ 深层语音分析” 技术开发的一款软件, 根据语音情感分析说话人的心理压力, 从而推断其说话内容的真实性[10]。 LVA语音系统在国外的推广应用中取得了非常突出的成果, 目前在我国的司法工作中只是作为一种辅助侦查的手段, 不能作为证据来使用, 即使是这样LVA语音系统依然可以为侦查人员提供线索和依据, 有利于案件的侦破。
人类可以通过听觉, 根据语速、音强、清晰度、声音质量来判断情感[11], 人在生气、恐惧的时候语速普遍略快, 而在悲伤的时候表现出来的语速就相对略慢。在生气、高兴时, 音强都比较高, 处在恐惧的状态下, 则较低, 但高于悲伤时。在生气的时候, 声音中有呼吸声、胸腔声; 高兴和悲伤的时候有共鸣声; 恐惧则表现出不规则的声音[12]。LVA语音系统提取语音中150多个参数, 精确地发现和测量声波中无意识的变化, 并创建一个实时的情绪图像。通过“ 情绪图像” 可以直观地看出说话人的情绪变化。语音系统从多个层面探索说话人有意或无意识的思维, 发现大脑的活动“ 痕迹” 。LVA语音系统有别于传统的测谎仪, 传统意义上的测谎仪是依靠许多仪器来监测说话人的心跳、血压、呼吸及脑电波等, 来判断说话人是否说谎, 说话人知道“ 测谎仪” 的存在, 如果说话人受过专门的训练、具有很强的实践经验, 那么测谎的结果就可能出现很大的偏差, 从而误导侦查人员的思维。LVA语音系统是通过分析人的语音, 发现语音背后的秘密, 可以在说话人完全不知情的情况下进行, 这样就可以大大增加测谎的准确性。
参与实验的20名研究对象均为中国刑事警察学院的在校学生, 均为男性, 年龄在18~25之间。在文本设计上, 一部分设置为内容比较敏感的问题, 例如是否有过逃课经历, 是否有过作弊经历等; 另一部分设置为比较轻松的问题(例如学校饭菜质量如何等)作为对照实验的样本, 共设置20个问题。实验是通过一问一答的形式, 分别在两个不同的情景下录制, 第一次安排陌生老师模拟上级领导来学校做问卷调查, 测试期间被测对象不可相互交流, 以避免学生知道测试情况产生抵触心理(下文称情景一); 第二次告知被测对象本次实验的目的, 学生在回答问题的时候可以按照自己的想法随意回答(学生可以撒谎), 测试人员还是第一次实验的老师(下文称情景二), 实验设置情景二的目的是为了测试被测对象在知道测谎情况下的系统识别率。在测试完成后, 分别找学生谈话, 询问问题的正确答案以及测试当时的心理情况。录音地点为一个安静的会议室, 录音设备为OLYMPUS-LS12和INFOMEDIA PAW-V录音笔, 录音采样频率为44 100 Hz。系统集成了语音分割功能, 可以将整段的语音分割成若干的语音片段, 测试人员可以根据需求选择需要的语音片段进行分析, 删除与测试无关人员的声音以及噪声, 系统还可以标记多个人的语音, 实现对一段语音中多人语音分别分析处理。将录音笔录制的音频导入语音系统, 首先去除空白语音以及噪音, 将老师和学生的语音分开标记, 然后对学生的语音进行分析, 最终生成分析报告。
实验中测试人都是以简单句的方式回答问题, 如“ 我没有玩过、没有做过弊、没有抱怨过” , 简单的回答方式可以避免系统在分割语音样本时将一个回答分割成若干语音片段增加分析的难度。LVA语音系统对标记的每一个语音片段进行分析, 通过技术扫描识别到“ 情绪指示器” , 即在规定时间内产生的与正常说话人存在差异的样板序列。这些序列使用定量测量和统计规则可以测量和分析, 产生第二级语音系统使用的语音参数(如情绪水平、压力水平等)。系统选择最开始的几个语音片段或录音材料中最适宜的语音片段计算出测试人“ 自由情感” 的语音参数的基准线, 即测试人在正常情绪状态下语音参数的敏感度、稳定性的“ 平均值” 作为基准线。系统根据各个参数的基准线通过其特有的说谎压力公式计算出诚实基准线, 在分析每个语音片段时, 系统利用该语音片段提取的各参数通过说谎压力公式计算出一个属于该语音片段的谎言压力值, 该值与诚实基准线相比较得出谎言可能性, 计算出的值与诚实基准线偏差越大, 欺骗概率越高, 最后根据谎言可能性给出实话、高风险-弄虚作假等提示。
在每次实验过后与研究对象谈话, 询问问题的正确答案与模拟实验的答案对比, 从而判断研究对象在回答问题时是否存在说谎情况, 然后与系统识别出来的结果相比较, 从而得出系统正确识别率(正确识别问题数/全部问题数)。
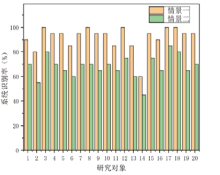
图1表示的是系统对20名研究对象在情景一和情景二中回答问题测谎的识别率。横坐标是研究对象编号, 纵坐标是系统的识别率。从图1中我们可以清楚地看出, 在情景一的情况下, 系统的识别率非常高, 平均识别率在91.75%; 在情景二的情况下, 系统的识别率明显低于情景一, 平均识别率只有68%。其中在情景一下, 参与测试的20名研究对象中, 有5名研究对象的识别率在100%, 占25%; 有8名研究对象的识别率在95%, 占40%, 只判断错了一个问题; 有2名研究对象的识别率在90%, 占10%, 有2个问题判断错误; 有5名研究对象识别率在90%以下, 占25%, 识别率分别为3人85%, 1人80%, 1人60%。LVA语音系统的识别率都在60%以上, 识别率在80%以上占了90%, 由此可见, 在说话人不知情的情况下, 系统具有非常好的识别效果。在情景二下, 只有3名研究对象的识别率在80%以上, 但是, 只有研究对象2和14的识别率在60%以下。就实验的总体情况而言, 研究对象14在情景一中, 共有12个问题撒谎, 系统只识别出4个问题; 在情景二中, 共有12个问题撒谎, 系统只识别出1个。在20 名研究对象中对象14的识别率最低, 这说明研究对象14有较好的伪装能力, 十分强的心理素质。研究对象17在本次实验中的识别率是最高的, 在情景一中, 有10个问题撒谎, 系统全部识别出来; 在情景二中, 共有8个问题撒谎, 系统识别出5个, 这说明研究对象17的说谎能力较差, 不善于伪装。从图1中可以清楚地看出, 虽然在情景二中的识别率明显低于情景一, 但是系统对每个人的识别率有一定的规律。在情景一中系统对研究对象3、8、12、17、18识别率较高, 在情景二中识别率依然要高于其他研究对象, 研究对象14不管是在情景一还是情景二的识别率都低于其他研究对象。
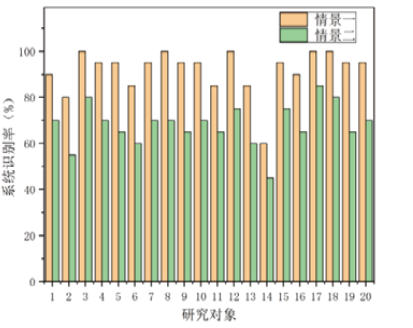 | 图1 在不同情景下系统的识别率Fig.1 System, s recognition rate under different scenarios |
在系统测试完成后, 会对每个研究对象生成一份分析报告, 其中包括情绪水平、压力水平、高SOS(say-or-stop)发生率等参数, 将数据汇总如表1所示, 测试人员可以根据生成参数进一步对研究对象进行分析。情绪水平反映问题对测试人引起的情绪变化, 正常男性:100~300, 正常女性:200~400; 压力水平反映研究对象恐惧的状态和问题引起的负面激励, 正常水平:26~35。从表1可以看出, 情景一和情景二中的情绪水平均要高于正常水平, 但是情景二比情景一低, 整体平均值低12.37%。在压力水平上, 情景二的总体水平低于情景一, 两个情景的整体平均值均在正常范围内, 在情景一中, 5名研究对象属于正常偏高, 只有研究对象14低于正常值, 比所有研究对象的平均值低37.69%; 在情景二中, 只有研究对象6的压力属于正常偏高, 其余研究对象的压力均为正常或正常偏低。不论是情绪水平还是压力水平的整体数据标准差, 情景二都比情景一高, 说明情景一比情景二中数据的离散程度小, 情绪水平和压力水平较相近。在所有研究对象中识别率最低的为研究对象14, 在情景一中的识别率为60%, 在情景二中的识别率只有45%。从表1中数据分析可得, 研究对象14与其他研究对象不同, 情绪水平和压力水平均低于其他研究对象, 说明研究对象14具有很好的心理素质, 即使在说谎的时候也能表现的非常自然。
本文采用双总体t检验的方式来检验情绪水平和压力水平在两个不同场景下平均数的差异性。将两种情景下20名研究对象的情绪水平和压力水平数据用SPSS进行分析, 两组数据的P值均小于0.05, 说明两组数据的均值有明显的差异, 也就说明情景一和情景二两种情景下, 情绪水平和压力水平有明显的差异。高SOS概率是指研究对象恐惧或回避问题的概率, 这里以研究对象6来说明:研究对象6在情景一中的高SOS概率最高, 达到了14%, 在20个问题中, 有6个问题回答时撒谎, 而系统只检测到其中3个; 在情景二中, 高SOS概率为3.3%, 在20个问题中, 有3个问题撒谎, 系统只检测到1个, 与高SOS的概率大致相同。在高SOS发生率上, 情景二比情景一的整体数据均值小, 可表明在情景二中全体研究对象出现高SOS的平均概率要小于情景一, 情景二比情景一的数据标准差小说明在情景二中全体研究对象之间高SOS发生率与情景一相比差异较小。
| 表1 系统生成的二级参数 Table 1 Secondary parameters generated by the system |
系统分析语音时能够随时生成压力参数和紧张参数, 统计每个问题的高压力和高紧张次数, 如表2。就总体而言在情景一中每个问题出现高压力、高紧张的次数均高于情景二。在情景一中, 问题1出现高压力、高紧张的次数最多, 这说明研究对象处于陌生环境和未知情形下的心理状态异常紧张。设置问题中包括了中性问题和一些涉及隐私的问题, 在涉及隐私及利害关系的问题中, 出现高压力和高紧张的次数明显多于中性问题。
| 表2 每个问题产生高压力、高紧张的次数 Table 2 Times of high pressure/tension triggered from each-asked question |
从20个问题中选择没有涉及隐私、没有利害关系的中性问题, 如自我介绍、学校饭菜质量如何、是否自己坐过火车等问题, 统计出现高度紧张、高度压力的次数。在涉及问题中, 1、2、3、12、13、14、16、17、18这些问题是中性问题。结果如图2所示。从图2a可以看出, 随着测试时间的推移, 出现高压力、高紧张的次数是呈下降趋势的, 说明研究对象的心理压力是逐渐下降的。将问卷的全部问题中的高度紧张、高度压力的次数统计出来, 如图2b, 从图中可以看出, 全部问题的压力趋势不再像中性问题那样随着时间的推移而逐渐下降。与图2a相比较, 可以发现出现高紧张、高压力频率高的问题都是相对尖锐的问题如考试期间作过弊吗、上课玩过手机吗、对警务化制度是否有过抱怨等。对于这些尖锐问题, 当研究对象心理有所波动时, 系统可以灵敏地检测出来。
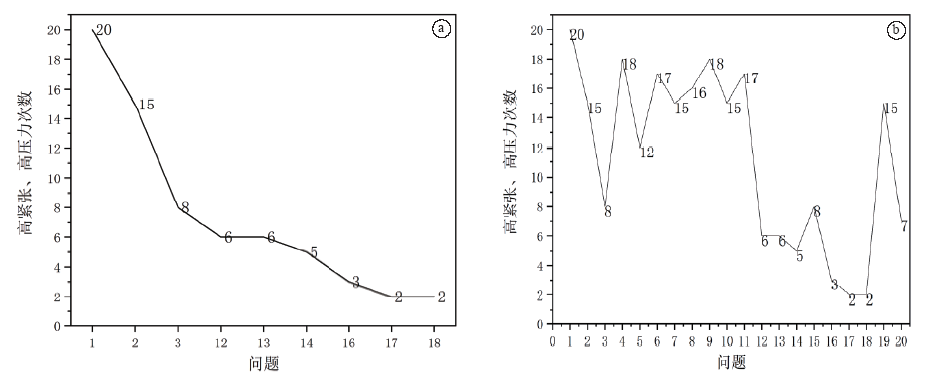 | 图2 压力趋势(a:中性问题; b:全部问题)Fig.2 Pressure trends from the neutral (a) and the all problems (b) |
本文通过实验对LVA语音系统进行测试, 在不同的情景下, 测试系统的识别率, 通过分析系统生成的数据分析被测人心理变化。实验结果表明:系统对不知情的说话人进行测试的效果非常好, 平均识别率为91.75%; 在研究对象知情的情况下识别率非常低, 平均识别率仅有68%。在测试过程中, 随着时间的推移研究对象的心理压力逐渐下降, 但敏感问题依然会使研究对象产生抵抗心理和紧张情绪。测试模拟现实, 对LVA语音系统能够应用到各个行业起到了非常重要的作用, 下一步将研究影响系统识别率的因素, 以提高系统的识别率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|