
{kind=link}
{kind=link}
{kind=link}
基于微信聊天记录时间信息的人物关系刻画技术研究
[康艳荣1  , 赵露
, 赵露1 , 范玮2 , 张紫华3 ]
, 赵露|
|


第一作者简介:康艳荣(1980—),女,河北乐亭人,硕士,副研究员,研究方向为电子物证。E-mail:kangyanrong@cifs.gov.cn
以微信为代表的通信工具每天都在产生可以描述人物关系的海量数据,如何通过数据整合为侦查办案提供智力资源和知识服务已成为大数据环境下公安机关科研工作的研究重点和难点内容。本文以微信聊天记录的时间信息为研究对象,利用分层聚类和K-均值聚类分析技术,发现通信时间特征与人物关系之间的关联关系,将微信联系人按照“亲疏远近”的人物关系进行分类,从而为案件侦查过程中快速寻找犯罪团伙、重点嫌疑对象提供一种新的技术手段。
Wechat, presently one of the most popular communication tools, is everyday generating huge quantity of data that can be used to profile people’s relationship. Therefore, it is becoming the research focal points, albeit also difficult to attain, that how to integrate and mine the massive data is about to provide intelligent source and knowledge service for criminal cases investigation. In this paper, the time information was taken as the studied subject that was extracted from the Wechat’s record so that the relationships of Wechat’s contractors can be classified through finding the correlative time characteristics by Hierarchical clustering and K-means clustering analyses. Thus, this research is potential of providing new resorts for quickly searching criminal gangs or key suspects during case investigation.
数据的爆炸增长、广泛可用和巨大数量使得我们的时代成为真正的数据时代, 急需功能强大的工具从海量数据中发现有价值的信息, 并把这些数据转化成有组织的知识[1]。经过近几十年的发展和完善, 数据挖掘技术已经日益成熟, 其主要方法有关联规则挖掘、分类与预测、聚类分析、遗传算法、文本挖掘、Web挖掘等[2]。社交工具及应用作为新兴媒体的代表, 其本身所携带的社交信息、交流信息以及社交用户产生的大量文本、图像、音频、视频等内容对于数据挖掘来说又是挑战[3]。现在流行的在线社交工具如推特、脸书、博客、微博、微信等通常都含有大量的链接数据和内容数据, 其中链接数据主要为图形结构, 表示两个实体之间的通信, 而内容数据则包含有文本、图像以及其他网络多媒体数据[4]。以海量数据为支撑的对人物关系的量化研究正日益得到重视。目前, 基于链接的分析主要致力于链接预测[5]、社区发现[6]、社交网络进化[7]和社会影响分析[8]等领域; 而基于内容的分析主要聚焦于关键字搜索、分类、聚类和异构网络中的迁移学习[9]等方面。近年来, 有学者不断提出了基于新方法的人物关系的定量分析, 如基于聚类分析(依据距离和相关系数来评估不同样本在属性上的相似性)与关联分析(分为同类事件的简单关联和不同事件的次序关联)的方法获取人物关系等[10], 也有学者利用关系抽取技术, 扩展传统的二元关系, 提出了一种基于同义词词林的抽取关系描述词的方法, 并通过该方法在收集一定量特定领域内的人物关系信息的条件下实现人际网络的定量分析及结果的可视化[11], 这在一定程度上促进了人物关系刻画技术的发展。本文在前人及笔者之前的研究[12]基础上, 以微信聊天记录的时间信息为研究对象, 首先对微信聊天记录数据进行预处理, 包括文件格式转换、数据结构定义、计算变量选取, 接着按照微信聊天形式将其抽象为会话段数、会话时长和响应时间三个要素并使用聚类算法对其进行量化研究, 最后对使用不同算法得到的数据结果进行了对比分析, 发现了会话段数与联系紧密度、响应时间与联系倾向性等关系, 为案件侦查过程中快速寻找犯罪团伙、重点嫌疑对象提供了一种新的技术手段。
定义1.1 秒差:接收者从接收到上一条会话时间至发送出本条会话时间的时间差, 秒差的取值范围为0~N(N≥ 0)。
定义1.2 首次响应时间:一段会话中接收者首次对接收的最近一条会话进行响应所花费的时间。
定义1.3 一般响应时间:一段会话中除首次响应时间之外的发送者和接收者之间的所有会话所花费时间之和的平均值。
定义1.4 会话时长:一段会话中发送者和接收者之间的所有会话所花费的时间和。
定义1.5 会话段数:按照番茄工作法, 将发送者和接收者之间的聊天记录以20 min为一个时间段进行划分。
定义1.6 会话总时长:所有会话段数的会话时长之和。
定义1.7 首次响应时间均值:发送者和接收者所有会话段数中的首次响应时间和的平均值。
定义1.8 一般响应时间均值:发送者和接收者所有会话段数中的一般响应时间和的平均值。
定义1.9 未响应次数:20 min内单独存在的一条会话的个数。
本文选取机主Andy与其78个微信好友的聊天记录数据为实验数据, 在SPSS软件中使用如下命令进行数据预处理:
1)将会话按条进行编号:“ COMPUTE 会话编号=$CASENUM. EXECUTE.” 2)计算变量“ 秒差” :“ COMPUTE 秒差=发送时间 - LAG(发送时间). EXECUTE.” 3)将“ 秒差” 大于20 min的该条会话标记为一段会话的开始:“ IF (秒差> 1200) 会话标记=1. EXECUTE.” 4)选取“ Andy发起的会话段数” 并生成新的变量:“ IF (发送者= 1) Andy=会话标记. EXECUTE.” 5)选取“ 好友发起的会话段数” 并生成新的变量:“ IF (发送者= 0) 好友=会话标记. EXECUTE.” 6)计算变量“ 单条会话时间” :“ COMPUTE 单条会话时间=秒差. EXECUTE.” 7)将“ 单条会话时间” 限定在2 min以内:“ IF (单条会话时间> 120) 单条会话时间=120. EXECUTE.” 8)将一段会话的首条会话所花费的时间限定为2 min:“ IF (会话标记=1) 单条会话时间=120. EXECUTE.” 9)选取“ Andy的单条会话时间” 并生成新的变量:“ IF (发送者 = 1) Andy1=单条会话时间. EXECUTE.” 10)选取“ 好友的单条会话时间” 并生成新的变量:“ IF (发送者 = 0) 好友1=单条会话时间. EXECUTE.” 11)计算变量“ 响应时间” :“ IF (发送者 = LAG(发送者)) 响应时间=发送时间 -LAG(发送时间). EXECUTE.” 。
机主Andy的78位好友中, 有50位好友“ Andy发起的会话段数” “ Andy未响应与已响应次数之比” 和“ Andy一般响应时间的均值” 中的一项或多项的值缺失, 本次样本分层聚类只选用其余28位好友数据进行分析。
2.2.1 操作步骤
在SPSS软件中依次点击:“ 分析” → “ 分类” → “ 系统聚类” , 进入“ 系统聚类分析” 对话框; 将“ Andy发起的会话段数” “ Andy未响应与已响应次数之比” 和“ Andy一般响应时间的均值” 选入“ 变量” 栏, 在“ 聚类” 中选择“ 个案” , 并输出“ 统计量” 和“ 图” ; 单击“ 统计量” 按钮, 在对话框中选择“ 合并进程表” “ 相似性矩阵” , “ 聚类成员” 里选择“ 方案范围:最小聚类数为2, 最大聚类数为10” ; 单击“ 绘制” 按钮, 在对话框中选择“ 树状图” , 在“ 冰柱” 栏中选择“ 所有聚类” ; 单击“ 方法” 按钮, 在对话框中选择“ Ward法” 聚类方法, 在度量标准中选择“ 平方Euclidean距离” , 在“ 标准化” 中选择“ Z得分” ; 单击“ 保存” 按钮; 返回主对话框, 在“ 标注个案” 中选择“ 好友名称” , 单击“ 确定” 。
2.2.2 命令分析
DATASET ACTIVATE 数据集1.
PROXIMITIES Andy发起的会话段数 Andy未响应与已响应次数之比 Andy一般响应时间的均值 /MATRIX OUT(‘ C:\Users\admin\AppData\Local\Temp\spss19776\spssclus.tmp’ )
/VIEW=CASE
/MEASURE=SEUCLID
/PRINT NONE
/ID=好友名称
/STANDARDIZE=VARIABLE Z.
CLUSTER
/MATRIX IN(‘ C:\Users\admin\AppData\Local\Temp\spss19776\spssclus.tmp’ )
/METHOD WARD
/ID=好友名称
/PRINT SCHEDULE CLUSTER(2, 10)
/PRINT DISTANCE
/PLOT DENDROGRAM VICICLE
/SAVE CLUSTER(2, 10).
ERASE FILE=’ C:\Users\admin\AppData\Local\Temp\spss19776\spssclus.tmp’ .
2.2.3 聚类结果
实验得到的近似矩阵表(如表1所示)说明, 近似矩阵中的数值越小, 表明二者距离越近; 数值越大, 表明二者距离越远。以“ Lucy” 为例, 距离“ Lucy” 最近的是“ Merry” , 距离“ Lucy” 最远的是“ F5” 。
| 表1 近似矩阵(节选) Table 1 Approximate matrix (excerpted) |
实验得到的Ward联结聚类表(如表2所示)说明, 距离最近的个案最先聚合, 如“ 11” 与“ 23” , “ 27” 与“ 28” , “ 19” 与“ 20” , “ 13” 与“ 15” , “ 8” 与“ 14” , “ 9” 与“ 25” 等, 直到出现阶群集。
实验所得的群集成员表(如表3所示)说明, 当聚类数为“ 2” 时, 只有F5单独一组, 该样本在分类为“ 3” 、“ 4” 、“ 5” 等时都被单独分成一组, 据此可以判定该个案的特殊性。
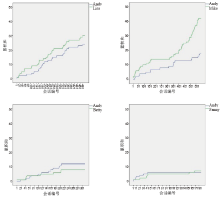
实验所得Ward联结的树状图(如图1所示)说明, “ 类” 间的距离越大说明区别越明显, 如“ Merry” 和“ Lucy” , “ C1” 和“ G3” , “ Betty” 和“ Dave” 这三组个案因两两之间的相似性以及与其他分类的差异性而被独立出来。
结合近似矩阵、Ward联结聚类表、群集成员和树状图, 我们发现当聚类数分别为8、6、4的时候, 聚类效果最为明显。
| 表2 Ward联结聚类表 Table 2 Results from Ward-joint clustering |
| 表3 群集成员 Table 3 Clustered Members |
 | 图1 会话段数与联系紧密度Fig.1 Session Segments and Relational Clossness |
依旧选取机主Andy的28位“ Andy发起的会话段数” “ Andy未响应与已响应次数之比” 和“ Andy一般响应时间的均值” 三项数据不缺失的好友数据为实验数据。由于这三项数据的单位不一致, 在快速样本聚类之前, 需要先进行标准化处理。依次点击:“ 分析” → “ 描述统计” → “ 描述” , 进入“ 描述性” 对话框; 将“ Andy发起的会话段数(变量1)” “ Andy未响应与已响应次数之比(变量2)” 和“ Andy一般响应时间的均值(变量3)” 选入“ 变量” 栏, 在对话框下方选择“ 将标准化得分另存为变量” 。单击“ 确定” , 得到的标准化数据。
3.2.1 操作步骤
在SPSS软件中依次点击:“ 分析” → “ 分类” → “ K-均值聚类” , 进入“ K-均值聚类分析” 对话框; 将“ Andy发起的会话段数” “ Andy未响应与已响应次数之比” 和“ Andy一般响应时间的均值” 选入“ 变量” 栏, 在“ 聚类数” 中填入“ 6” , 在“ 方法” 中选择“ 迭代与分类” ; 单击“ 迭代” 按钮, 在对话框中填入“ 最大迭代次数为10, 收敛性标准为0” ; 单击“ 保存” 按钮, 在对话框中选择“ 聚类成员” ; 单击“ 选项” 按钮, 在“ 统计量” 中选择“ 初始聚类中心、ANOVA表、每个个案的聚类信息” , 在“ 缺失值” 中选择“ 按列表排除个案” ; 返回主对话框, 在“ 个案标记依据” 中选择“ 好友名称” , 单击“ 确定” 。
3.2.2 命令分析
QUICK CLUSTER Andy发起的会话段数 Andy未响应与已响应次数之比 Andy一般响应时间的均值
/MISSING=LISTWISE
/CRITERIA=CLUSTER(6) MXITER(10) CONVERGE(0)
/METHOD=KMEANS(NOUPDATE)
/SAVE CLUSTER
/PRINT ID(好友名称) INITIAL ANOVA CLUSTER DISTAN.
3.2.3 聚类结果
实验所得的最终聚类中心距离表(如表4所示)在一定程度上反映了各个类别之间的区分情况, 第1类与第3类的距离最大, 区分度最好; 第1类与第5类的距离最小, 区分度最差。类似地, 第3类与所有其他类别的区分度都非常好, 而第5类与除第3类外的所有其他类别的区分度都一般。
| 表4 最终聚类中心间的距离 Table 4 Distance among the final clustered centers |
实验所得的方差分析表(如表5所示)说明, 本次参与聚类分析的三个变量中的任意一个变量的“ 类间均方” 都远远大于“ 类内的误差均方” 。从概率上看, 这三个变量使六个分类之间无差异的假设成立的概率都小于0.05%, 这说明该三个变量能够很好地区分各类, 聚类的效果是显著的。其中, “ 变量1” 对聚类的贡献最大, “ 变量3” 对聚类的贡献最小。
结合最终聚类中心间的距离、方差分析, 当聚类数预先设定为“ 6” 时, 聚类的整体效果最为明显。
| 表5 方差分析 Table 5 Analysis of variance |
将样本分层聚类结果整理成表6, K-均值聚类结果整理成表7, 通过对比分析得到如下结论:第一, 上述两种聚类方法得到的结果非常相似, 但在“ Dave” 的归属上, 样本分层聚类认为其是属于“ 不紧密且非常积极” 类, 而K-均值聚类认为其是属于“ 一般紧密且积极” ; 在“ C1” 的归属上, 系统聚类认为其是属于“ 不紧密且一般积极” , 而K-均值聚类认为其是属于“ 不紧密且非常积极” 。第二, “ Andy” 与微信好友的联系呈现出“ 扁平化” 结构。第三, 第一类和第六类的好友数量非常少, 而第三类和第四类的占比达到了57%。这说明“ 极好” 与“ 极差” 的好友是少量的, 大部分的好友都是处于“ 不紧密” 但“ 非常积极或积极” 的状态。从分类的效果以及聚类成员的分布来看, 这两种聚类的结果除个别样本外, 都相互得到了印证, 具有比较高的可靠性。
| 表6 样本分层聚类结果 Table 6 Results from clustering the layered samples |
| 表7 快速样本聚类结果 Table 7 Results from K-means clustering |
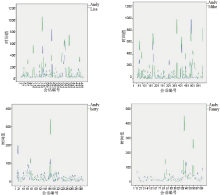
选取上节中“ 一般紧密且积极” 的Lisa和Mike、“ 不紧密且非常积极” 的Betty和Fanny与Andy之间的会话段数累积和、一般响应时间进行数据分析, 将“ Andy发起的会话段数” 和“ 好友发起的会话段数” 的累积和用多线线图表现出来对比后发现“ 一般紧密” 的会话段数与“ 不紧密” 相比, 具有明显的连续递增的趋势, “ 一般紧密” 的累计和明显大于“ 不紧密” 的累计和, 如图2; 将“ Andy花费的一般响应时间” 和“ 好友花费的一般响应时间” 的值用多线线图表现出来对比后发现“ 积极” 的一般响应时间与“ 非常积极” 相比, 具有明显的波动性, “ 非常积极” 的一般响应时间的“ 值” 明显比“ 积极” 的一般响应时间的“ 值” 更集中, 如图3。
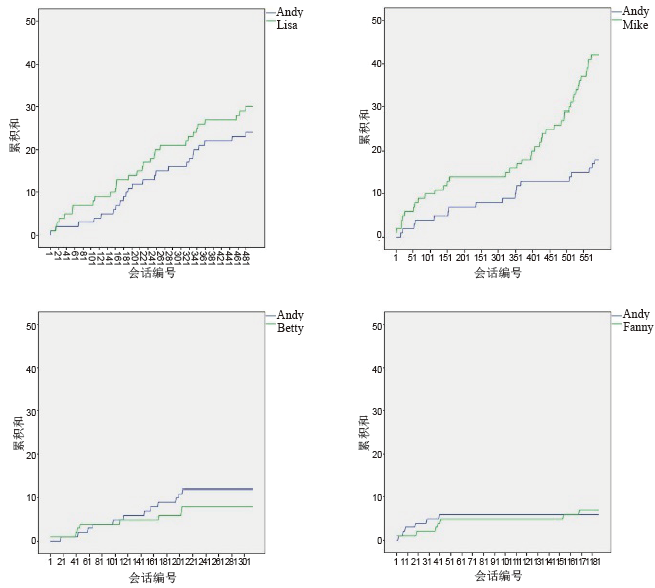 | 图2 会话段数与联系紧密度Fig.2 Session Segments and Relational closeness |
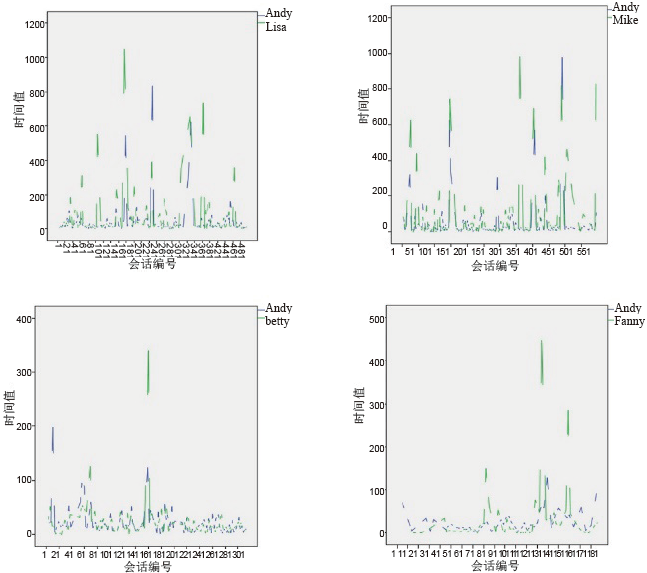 | 图3 响应时间与联系倾向性Fig.3 Responding time and contact tendency |
本文通过对微信好友聊天数据时间特征进行研究, 设定了若干能反映“ 联系紧密度” 和“ 联系倾向性” 的变量, 然后对选定参与聚类的变量进行了样本分层聚类和K-均值聚类, 并对聚类结果进行了对比分析。经过分析和论证, 本文采用的以“ 发起的会话段数” 、“ 未响应与已响应次数之比” 和“ 一般响应时间的均值” 为变量对人物关系的“ 亲疏远近” 进行分类的方法能够反映客观的实际情况, 可以用于案件中人物关系分析。同时, 本文在实验中发现, 即使在同一个分类里面, 各个成员之间依然各有差异, 例如对“ 联系一般紧密” 及以上的个案进行“ 联系倾向性” 分析, 就会找到“ 熟悉的陌生人” , 即那些“ 活跃” 在我们身边, 却被我们“ 冷落” 的人。接下来, 本文将针对单变量对人物关系的影响、聚类过程中的异常值分析等展开深入研究, 以期获得更有价值的发现。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|