




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Excel 2003文件碎片检验方法研究
[徐国天 ]
]
]
|
|


作者简介:徐国天(1978—),男,辽宁沈阳人,硕士,副教授,研究方向为电子物证。E-mail:459536384@qq.com
目的 在实际办案工作中,我们发现存在这样一种情况,被删除的涉案Excel文件仍有大量数据残留在磁盘内,但是现有数据恢复工具却无法成功恢复。本文尝试建立一种手工提取残留Excel数据碎片的检验方法。方法 首先确定原始Excel文件中的一组数据作为搜索特征值,之后使用winhex在磁盘空间内定位这组特征值,再通过人工分析方式排除误报,提取有效数据。结果 使用本文提出的手工分析方法可以准确定位Excel数据碎片中的某个字段值,由于Excel的数据内容都在相邻扇区内存储,因此可以从相邻扇区提取出所有残留的字段值,再根据这些字段值之间的逻辑关系确定这是否为一个有效的Excel碎片。最后利用各个字段值的具体内容和不同字段值之间的逻辑关系来还原原始的Excel表格。结论 使用本文提出的手工分析方法可以有效提取磁盘内残留的Excel数据碎片,恢复某些现有工具所不能提取的Excel数据。
Objective In practice, the deleted Excel file is usually found of leaving with a large number of residual data in the disk. However, the existing tools of data recovery cannot successfully restore them, incapable of using these important clues. This paper tries a method to manually extract such Excel data fragments.Methods A set of data in the original Excel file are firstly selected as the feature values for search so that they can be located by WinHex at a specific space in the disk. Through the manual analysis to exclude the invalid data and extract the effective ones, the whole original Excel file will be likely to be recovered. For the manual analysis, how to define the value of the searched feature is the key. If the number of bytes is too small, a number of false alarms will emerge; on the contrary, the important clues will be lost. Therefore, many groups of key words are required to test so as to ensure that any set of traces do not be missed.Results Some fields that exist in the Excel data fragments had been accurately located. As the data of a whole Excel document are usually stored in the adjacent sectors of a disk, thus all the remaining field values are able to extract from these places. Finally, the logical relations between different field values were utilized to have the original Excel file restored.Conclusion The method established here can effectively extract the residual Excel data fragments in the disk, capable of restoring the Excel file that cannot be recovered by the already-existing tools.
Excel是Office办公软件集的一个重要成员, 它有比较强大的数据存储和处理能力, 操作简单、快捷。Excel文件中存储的数据信息对公安机关的调查、取证工作有重要意义。犯罪分子为了逃避法律的制裁, 会恶意删除或修改涉案Excel文件中的关键数据, 如何恢复这些数据信息是值得研究的课题。
在实际工作中我们发现存在这样一种现象:被删除的涉案Excel文件仍有大量数据残留在磁盘内, 但是现有数据恢复工具(如Final Data、取证大师)的自动恢复功能却无法成功恢复, 导致重要线索的遗失。本文对这一现象展开研究, 分析Excel文件碎片的形成原因、研究现有工具的自动恢复功能无法有效恢复Excel数据碎片的机理, 提出Excel文件碎片的手工检验方法。本篇论文的研究对象为2003版Excel文件, 2007版以上的Excel文件采用ZIP压缩格式存储, 不适用本文介绍方法。对2007版以上Excel数据碎片的恢复方法另行研究。
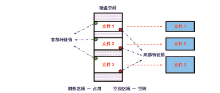
现有数据恢复工具(如Final Data、取证大师)的自动恢复功能普遍采用基于文件首尾特征值的数据恢复方法[1]。图1显示的是一块硬盘的存储空间, 阴影区域代表已被某些文件使用的存储空间, 空白区域代表空闲的、可以使用的存储区域。假设这时用户向硬盘拷贝了三个文件, 分别放置在这三块存储空间内, 随后用户删除了这三个文件。删除之后, 文件数据并没有从磁盘内消失, 只是这三块空间的存储状态由已占用状态重新变换为空闲状态。
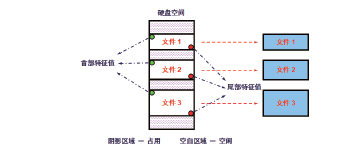 | 图1 现有数据恢复工具采用的首、尾特征值恢复方法Fig.1 The on-going recovery by utilization of the characteristic values of the head and tail |
由于每类文件都有固定的首部和尾部特征值[2], 例如Excel文件的起始8个字节数据固定为:D0 CF 11 E0 A1 B1 1A E1。现有数据恢复工具可以从这三块存储空间内识别出三组文件首部特征值和尾部特征值。利用这三组首、尾特征值可以确定每个文件的起始和结束位置, 进而完成文件恢复。
在实际应用当中我们发现现有数据恢复工具的自动恢复功能存在一个比较严重的应用缺陷, 某些文件被删除之后, 虽然这些文件仍有大量数据残留在硬盘内, 但是现有软件却无法成功恢复[2]。
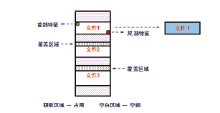
仍然用上文的例子来说明。这三个文件被删除之后, 随着计算机的使用, 文件2和文件3的首部存储空间被其它文件重新使用, 导致这两个文件的首部特征值被覆盖破坏, 文件2和文件3残留数据即为碎片。现有数据恢复工具只能提取到文件1的首部和尾部特征值, 进而恢复文件1, 而无法识别出文件2和3的首部特征值, 导致这两个文件虽然仍有大量数据残留在磁盘内, 但是使用现有工具的自动恢复功能却无法成功恢复(见图2)。
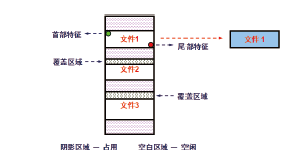 | 图2 数据碎片无法有效恢复原因分析Fig.2 The reason why the data fragments cannot be effectively recovered |
对于Office文档、数据库、图片等结构化文件, 其内部数据有固定的存储特征值, 可以根据这些特征值定位到数据碎片, 再进一步识别出文件残留数据的起始和结束位置, 进而完成文件恢复, 利用这种方式可以恢复现有工具所不能恢复的一些数据文件。
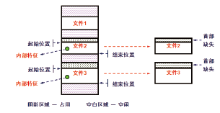
图3说明了这种恢复方法。根据文件内部数据特征值定位到文件2和3的数据碎片, 再确定两个碎片的起始和结束位置, 进而完成碎片提取。但是利用这种方式恢复出的数据文件通常首部结构已经缺失, 导致这些文件无法正常使用。因此需要对这些残缺文件进行修复, 使其可以正常使用。
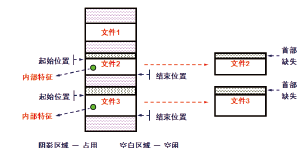 | 图3 数据碎片的定位和提取Fig.3 Location and extraction of data fragments |
对于轻度破损的文件, 即只是文件首部和尾部数据遭到破坏, 中间绝大部分数据并未遭到破坏, 这时可以通过补充头部和尾部数据结构的方式进行修复, 使其还原为一个可以正常使用的完整文件。
对于重度破损的文件, 即文件各段数据均遭到严重破坏, 已无法通过增补头、尾数据结构的方式来进行修复。此时提取出文件中残留的文字、图片和表格数据, 分类呈现给检验人员。
下面通过一起真实的案件说明Excel数据碎片的检验方法。案情简介如下:某派出所于2016年4月11日接到辖区某市场报案称其门口保安及收银员使用打假票据的方式私自侵占公司货车进车费, 非法获利80余万元。经查, 犯罪嫌疑人在收银电脑中新建一个Excel表格, 在表格内模仿公司收费软件打出三联票据, 私自侵占公司货车进车费。送检物证包括Intel硬盘一个, 容量为60G。要求对送检的硬盘中犯罪嫌疑人打印假票据使用的Excel表格内容进行恢复, 查找其打印过的假票据数量。
办案人员复制了涉案硬盘, 所有检验均在复制硬盘中进行, 以保证被检验数据的完整性和有效性。使用Final Data和取证大师的自动恢复功能对复制硬盘进行了全盘扫描, 未提取到任何涉案Excel文件数据。
通过对案情进一步了解, 初步找到了造成这一现象的原因。为了掩盖犯罪痕迹, 嫌疑人打印假票据之后, 很少向硬盘保存数据, 即使保存了少量文件, 也会尽快删除。因此在硬盘内残留的Excel痕迹非常少, 且均破损严重, 导致使用现有数据恢复工具的自动恢复功能提取不到任何涉案数据。
手工提取Excel数据碎片步骤如下:首先确定原始Excel文件中的一组数据作为搜索特征值, 之后使用winhex在磁盘空间内定位这组特征值, 再通过人工分析方式排除误报, 提取有效数据。手工分析的关键点是如何确定搜索特征值, 如字节过少, 会导致大量误报现象。如字节过多, 会导致漏报现象。因此在实际操作过程中也需要测试多组关键词, 以保证不漏掉任何一组痕迹。
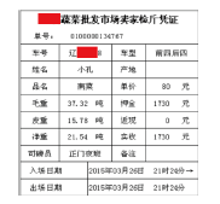
虽然没有原始Excel文件作为参考, 但是由于嫌疑人模仿的是正规收费软件打印出的三联票据, 因此我们可以在三联票据中寻找特征点, 图4为正规收费软件打印出的三联票据。在选取特征点时尽量选取重复多次出现的数据, 这样的数据即使几个特征点被覆盖了, 也仍可能有部分特征点遗留在磁盘内。相反, 如果选择出现次数较少的特征点, 一旦该特征点被覆盖, 即使残留了大量其它数据, 也无法有效提取。
按照这一原则, 在图4中“ 吨” 和“ 元” 均可以作为备选的特征点。但是如果直接在磁盘内搜索这两个数值会导致大量误报现象, 因此还需要增加特征点的字节长度。观察图4中的数据, “ 吨” 和“ 元” 与前面的数值数据之间存在一些距离。据此推测, 在Excel文件中, 这个区域应该存在若干个空格, 具体设置为几个空格需要实际测试确定。这些空格字符起到排除歧义的作用, 文中简称为排歧空格。这里初步确定两组特征点, 第一组为“ 空格 空格 吨” , 第二组为“ 空格 空格 元” 。
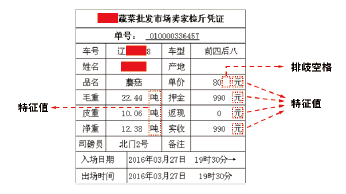 | 图 4 正规收费软件打印出的三联票据Fig.4 A printed bill to show the feature values |
接下来, 需要确定搜索特征点的十六进制编码。由于Excel文件默认采用Unicode编码保存数据, 因此可以新建一个文本文件, 输入特征值, 再将文件另存为Unicode编码格式。最后使用winhex打开文本文件, 即可查看到特征值所对应的十六进制数据。通过这种方法可以确定, 第一组特征点十六进制值为2000 2000 2854, 第二组为2000 2000 4351。
使用winhex在磁盘空间内搜索这两组特征值, 很快定位到图5所示第一组数据块。这组数据的起始位置是0X38E8A4200, 这个位置恰好为扇区边界, 前面的数据均为0X00, 说明之前的Excel数据已经被覆盖。在这组数据块中共提取出四组信息, 分别是“ 出场日期” 、“ 前四后四” 、“ 80 元” 和“ 0 元” 。
 | 图5 第一组数据块Fig.5 The first data set to locate the feature values |
因为涉案Excel文件中文字数据量很少, 只有十一行数据。因此在定位到一组特征点之后搜索范围可以确定为向上4个扇区和向下4个扇区, 在此区间内可以提取到所有残留数据。图6为在临近位置提取到的第二组数据块, 该数据块携带的信息为“ 单号:” “ 0 1 0 0 0 0 0 1 3 4 7 6 7” “ 2015年3月26日 21时24分→ ” 和“ 2015年3月26日 21时24分” 。
 | 图6 第二组数据块Fig.6 Second data set to locate the feature values |
图7为在临近位置提取到的第三组数据块, 该数据块携带的信息为“ 辽CG* * * 8” “ 小孔” “ 南菜” “ 37.32吨” “ 15.78吨” “ 21.54吨” 和“ 1730元” 。
 | 图7 第三组数据块Fig.7 Third data set to locate the feature values |
三联票据上的每项数据信息均由两部分组成, 即字段名和字段值, 例如“ 品名” 为字段名, “ 南菜” 为字段值。通过分析我们发现, 所有字段名数据集中存储, 所有字段值数据集中存储。在本例中所有字段名信息已经被覆盖, 无法提取。但是由于每张票据的字段名信息均为相同值, 因此这部分数据可以作为已知信息。图5~7提取出的每项字段值均可以从内容上区分出对应的是哪个字段, 因此可以得到图8所示的计算结果。
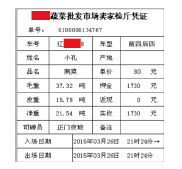 | 图8 提取出的Excel数据Fig.8 Excel file recovered by the extracted data |
利用这种手工分析方式, 在涉案硬盘中共提取到10组假票据信息。
为了防止出现漏检情况, 还需要更换不同的特征值进行多次检测, 以确保结果的准确性。作者选取了“ 入场日期” 和“ 出场日期” 中均携带的“ 日 空格 空格” 作为特征值对磁盘进行了再次搜索。
除了定位到之前那10组Excel数据碎片之外, 还提取到一些残留极少量数据的碎片块。图9为其中一个碎片块, 从这个数据块只提取到一个日期数据“ 2015年7月13日 21时24分” 。由于缺少其它关联信息的相互认证, 因此无法凭借这一条信息认定它属于涉案数据碎片。
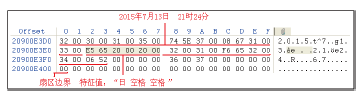 | 图9 残留极少量数据的碎片块Fig.9 One fragment that reveals only small amount of data |
本文研究了一种手工定位、提取Excel数据碎片的方法, 应用这种方法可以有效提取磁盘内残留的Excel数据碎片, 恢复某些现有工具的自动恢复功能所不能提取的Excel数据。但是如果涉案硬盘内残留的Excel数据碎片较多, 应用这种方法的操作效率就会降低, 因此作者计划在后续的研究工作中设计一款软件系统, 实现自动化的数据碎片定位和提取任务。
需要特别说明一点, 由于涉案数据为纯文本内容, 数据量很少, 因此数据被截断、处于不连续存储状态的可能性很小。如果出现这种情况, 应用本文提出的手工恢复方法可以提取到两个数据碎片, 但无法认定这两个碎片属于同一个原始Excel文件。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
| [1] |
|
| [2] |
|