
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于二维相关度的嫌疑人社交网络分析方法研究
[上官梦轩1  , 康艳荣
, 康艳荣2, * , 范玮3 , 张国臣2 , 赵露2 ]
, 康艳荣, 范玮|
|


第一作者简介:上官梦轩(1992—),男,浙江温州人,在读硕士生,研究方向为电子物证检验。E-mail:18611094681@163.com
构建和分析嫌疑人的社交网络结构有助于深入研究嫌疑人信息传播的规律,从而获取更多嫌疑人作案线索。现有的社交网络的相关度设计多忽略数据属性,本文将数据属性引入相关度中,并改进相关度数量值计算模型,提出了一种适用于手机实联系数据,通过数据属性与数据数量二维度相结合来描述手机拥有人与手机中存在的联系人间的相关程度的模型,我们将其定义为二维相关度模型。最后结合数据可视化技术分析嫌疑人社交网络。研究表明此方法能够有效的反映嫌疑人与联系人之间的相关程度,形象直观地呈现社交网络图,并能更有效的挖掘嫌疑人社交网络的隐含信息,更有利于工作人员后期工作的展开。该研究为分析嫌疑人社交网络提供了新思路,具有一定的现实意义。
The structure of suspect's social network is helpful to analyze the regularity of his/her information transmission, thus more clues about him/her can be obtained. However, most of the existing social network performers relating to correlativity ignore the attribute type of data. Therefore, an algorithm of two dimensional correlators was put forward with inclusion of the data attribute so as to improve the calculation of correlated data. A model was set up to describe the correlating extent between the owner of one mobile phone and the contacts kept in the phone when the data dimensions of both attribute and quantity were combined. This model can be used to orient real contacts through mobile-phone-storing data like short messages, callings and name list of communication. Finally, with the visualization devices introduced, a suspect’s social network can be visually revealed. Validity test showed that this manipulation can effectively measure the social intercourse between a suspect and his/her contacts by one intuitionistic social graph so that the implied information of the involved person will be further mined from his/her social network, more conducive for the following work to deploy. As a new idea to analyze suspect’s social network, the method attempted here certainly holds its practical significance.
社交网络分析是指通过科学的方法和度量方式来描述社交网络成员之间内在的联系并且突出网络中不同聚类的一种分析科学[1]。当前对在线社交网络的社群挖掘已经有了大量的研究, 其中国外较为著名的有Newman和Girvan提出的GN算法[2], 提供了一种社区划分的方法, 未提到相关度计算。国内也有许多学者研究在线社区的社交网络特点和社交特征挖掘, 例如, 解立群等[3]分析了微博用户信息传播的网络拓扑关系, 得出社交网络的“ 围观模型” 。张佰明等[4]研究了网络微博发展的根本逻辑, 发现社交网络的用户形成了一个又一个的子社群, 通过子社群之间的相互嵌套传播消息。有学者结合在线社交网络和犯罪调查进行了研究, 其中Mutawa等人就利用爬虫技术获取嫌疑人在facebook和twitter中联系人的情况并进行社交网络分析[5, 6], 但是此方法只是以出度和入度代替相关度。由于公安工作的特殊性, 往往需要对社交网络进行更加细致的分析以便发现隐含的信息, 因此, 我们将数据属性作为相关度的另一重要属性, 提出通过数据属性与数据数量二维度相结合来描述手机拥有人与手机中存在的联系人之间的相关程度的二维相关度模型, 并将二维相关度模型与数据可视化技术相结合建立一种基于嫌疑人手机数据分析嫌疑人社交网络的分析方法, 从而达到更精确的重构和分析嫌疑人社交网络的目的。
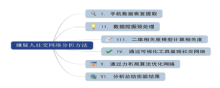
为实现基于嫌疑人手机数据的社交网络分析, 本文结合数据可视化技术建立一种基于二维相关度的嫌疑人社交网络分析方法, 此方法的研究流程包括数据提取、数据预处理、数据分类与相关度计算、社交网络可视化、可视化结果优化、分析实验结果。流程图和简介如图1所示。
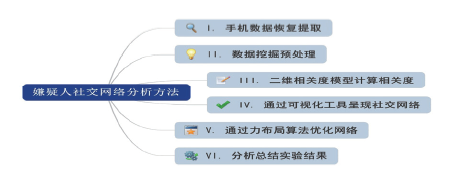 | 图1 嫌疑人社交网络分析方法结构图Fig.1 Structure of suspect’ s social network for analysis |
随着手机内存的增大, 数据量和数据形式都不断增多, 这对手机取证工作既是挑战也是机遇, 机遇在于手机中包含的信息越来越多, 挑战在于需要从大量的数据中寻找需要的信息。在数据提取阶段, 本文利用高奈特电子取证设备对手机进行数据提取, 为了便于寻找所需信息, 进一步将社交数据分类为实联系数据和虚联系数据, 实联系数据主要是传统联系方式产生的数据而虚联系数据则是通过新型互联网应用联系产生的数据。实联系数据基本都能利用手机号码进行唯一性标识并且可以以号寻人, 包括短信、通话记录、通讯录记录。虚联系数据主要利用互联网ID进行唯一性标识, 包括微信、QQ、陌陌等手机应用软件信息。本文主要研究对象为实联系数据。在取证过程中, 为避免提取数据被窜改, 选择以html格式输出数据。
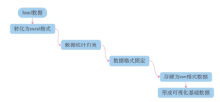
在1.1中通过高奈特设备所获取的html格式数据无法直接进行进一步的分析, 在本阶段需要将其转换为合适的文件格式便于进行进一步的分析, 在此通过利用格式转换与数据表存储的方法顺利地将html文件中所需的数据进行转化。数据的预处理我们主要是通过手动处理, 通过数据格式的多次转换和固定进行实现, 首先将html中的数据转移到excel中进行统计归类, 其次将excel数据进行数据格式的固定, 再次将excel储存为csv数据格式, 最后导入数据可视化工具中形成可视化基础数据, 流程如图2所示。
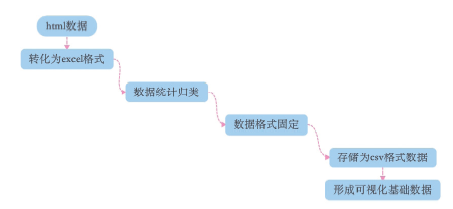 | 图2 操作流程Fig.2 Operation process to handle the data |
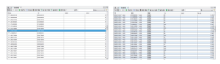
最后形成的数据可视化基础数据分为节点数据与边数据, 具体形式如图3所示。
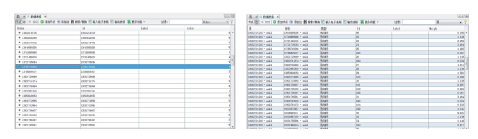 | 图3 节点数据(左)与边数据(右)Fig.3 Node data and edge ones |
上述的节点数据与边数据都是从手机提取的实联系数据转换而来, 其中节点数据表示手机实联系数据体现的所有联系个体。它主要有Node、Id、Label、Color四个属性, 都是用来说明点特征的属性, 其中Node表示点的序号, Id用来进行唯一性标识, Label表示点的标签信息, Color表示点的颜色。边数据表示点之间的联系, 主要有Source、Target、Id、Type、Weight五个属性, 用来说明边特征, 其中Source、Target用来表示具体的两点联系, Id进行边的唯一性标识, Type表示边的类型, Weight表示边的粗细程度, 由于本文在实联系数据统计时对其方向性不做要求, 所以将边的类型定义为无向边[7]。
基于获取的手机实联系数据构建和分析嫌疑人的社交网络, 需要具有针对性的相关度计算模型。本文提出了一种通过数据属性与数据数量二维度相结合来描述手机拥有人与手机中存在的联系人之间的相关程度的相关度模型, 我们将其定义为二维相关度模型。具体公式如(1)所示。

其中, i表示拥有手机的嫌疑人(主体), j表示嫌疑人i手机中的联系人(客体), 
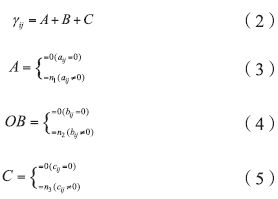
A表示i通讯录中是否存在j的联系方式, B表示i与j是否进行通话联系, C表示i与j是否进行短信联系。aij表示i通讯录中j联系方式记录条数, bij表示i与j的通话次数, cij表示i与j的短信条数, n1、n2、n3表示设置的常数, 为了将集合区分出来, 需要满足n1≠ n2≠ n3≠ n1+n2≠ n1+n3≠ n2+n3≠ n1+n2+n3, 所以我们令n1=1, n2=3 , n3=5。由此通过γ ij达到了将个体社交数据属性进行区分的目的, 但是, 仅仅通过γ ij体现关系度还是不足的, 本文在前人研究的基础上进行改进, 建立二维相关度的数量值。张星等[8]提出的相关度主要针对的是社交网络应用软件中的用户个体, 其分析数据是社交应用中的评论、转发和分享数据, 而本文研究对象是嫌疑人的社交对象, 分析数据为手机数据中的短信、通话和通讯录数据。两者即具有相似性, 又有差异性, 相似性在于目的都是计算客体之间的联系密切程度, 而差异性主要在于数据获取对象和数据形式的不同。张星等所设计的相关度模型将社交应用中的评论、转发、分享三种不同的数据整合到一起计算相关度, 并且根据三种数据在总体数据中的占比赋予其数据权重。但是由于数据形式的不同, 所以本文将三种不同的数据, 作为三个不同整体, 二维相关度数量值则是三个整体各自数据的叠加, 这种形式有利于提高通讯录数据重要性, 在对待手机通讯录数据方面, 我们联系实际分析发现:通讯录数据不同于短信记录与通话记录数据, 短信与通话的数量可以反映社交关系的密切程度, 但是对通讯录数据并不适用。所以我们将通讯录数据以存在与否作为赋值条件。具体计算公式如(6), (7)所示。
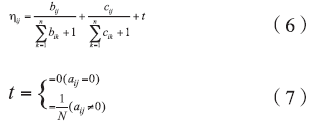
n表示主体i手机中联系人的总数, N表示主体i手机通讯录中联系人的总数。t表示数量值中通讯录数据提供的量值。aij、bij、cij表示对象在前文已经提到过。基于二维相关度 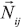
通过二维相关度模型, 我们将社交网络中的个体之间的关系表示为二维向量的形式, 为了将嫌疑人社交网络形象的呈现并且验证二维相关度模型的可行性, 我们结合可视化技术对嫌疑人社交网络信息进行分析。社交网络的可视化主要通过图论的知识来表示, 其定义为:

V表示节点, E表示线, 节点在社交网络中表示个体, 线在社交网络中表示联系, 在社交网络可视化过程中我们将二维相关度反映在节点和线的属性中, 其中数据属性反映为点的Color属性, 数据数量反映为线的Weight属性。通过开源软件Gephi来实现可视化。为进一步优化突出社交网络的特征, 通过加入力导向布局算法对社交网络进行优化布局可使研究对象的社交网络特征更加突出。在力导向布局算法[9, 10]中, 可视化图中主要存在的力有吸引力和斥力两种参数, 在本文中, 可视化节点间的吸引力和斥力主要和二维相关度模型中两者之间的相关度数量值相关联。在本文中我们通过实验将参数设置如下:惯性=0.1、斥力强度=1000、引力强度=0.05、最大位移量=10, 经过力导向布局算法的优化, 得到的可视化结果中, 距离中心区域距离越近的点, 表示其与嫌疑人主体的关系越密切。
为了评估基于二维相关度嫌疑人社交网络分析方法的可用性, 我们分别提取嫌疑人对象一与对象二的手机数据, 基于所采集的数据, 一方面我们通过数据统计比较了相同数据集下传统相关度值与二维相关度的数量值的差异, 证明改进的二维相关度数量值的计算模型的有效性。另一方面, 通过数据可视化比较了一维相关度(只保留相关度数量值属性)与二维相关度在社交网络构建和分析中的差异, 证明二维相关度中增加的数据属性值在数据分析中起到了作用, 由此证明二维相关度的有效性。
我们首先通过手机取证工具高奈特设备恢复提取了手机数据, 然后对获取的实联系进行数据预处理, 其中嫌疑人对象一的数据处理过程如图4所示。
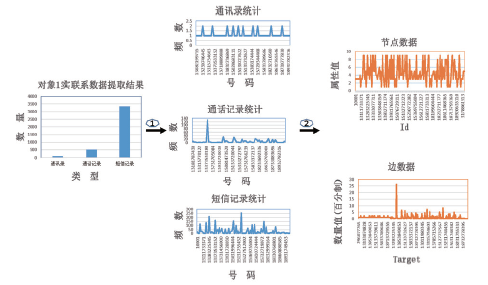 | 图4 对象一手机数据提取处理Fig.4 Data extraction from one mobile phone and processing |
其中过程①表示对提取的实联系数据依据手机号和数据类型进行统计, 过程②表示通过统计数据计算二维相关度, 并且将二维相关度的属性值与数量值分别反映在点文件的color属性与边文件的weight属性。
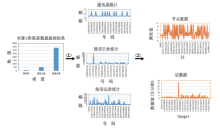
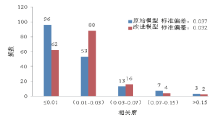
为了证明二维相关度中数量值属性计算模型的可行性, 基于2.1中采集的实验数据, 我们通过SPSS软件对原始模型与改进模型所获得的相关度进行描述统计-频数分析, 结果如图5所示。
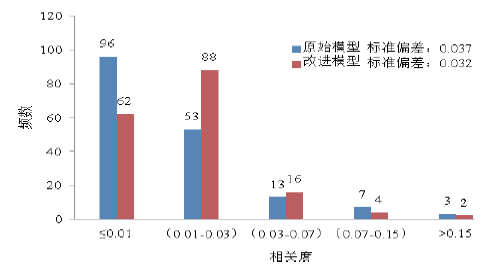 | 图5 描述统计-频数分析Fig.5 Descriptive statistics of frequencies relating to correlativity |
对比改进后的数量值计算模型与原始的相关度计算模型的计算统计结果可以发现:1)相关度小于等于0.01的客体人数明显降低。2)依据两者的标准偏差的不同可以发现改进模型的聚类能力更强。由此体现了二维相关度数量值计算模型的可行性。进一步地, 我们通过数据可视化技术呈现了获得的嫌疑人社交网络, 并且比较了一维相关度和二维相关度下的社交网络可视化结果。我们将二维相关度的属性值和数量值分别映射为可视化网络图中点的颜色与线的粗细。其中属性值表示所属集合与颜色的对应关系如图6所示。
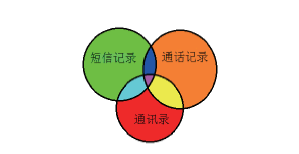 | 图6 属性值对映关系Fig.6 Relationship among attributes |
基于2.1中采集的实验数据, 通过可视化手段, 并且在原始的可视化的基础上利用力布局算法将可视化视图进行优化布局获得一维相关度可视化与二维相关度可视化结果图如图7、图8所示。
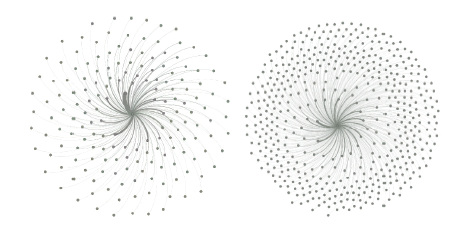 | 图7 一维相关度社交网络可视化结果图(左:对象一; 右:对象二)Fig.7 Visualization of social network with one dimensional correlator |
 | 图8 二维相关度社交网络可视化结果图(左:对象一; 右:对象二)Fig.8 Visualization of social network with two dimensional correlators |
对比一维相关度可视化与二维相关度可视化结果图, 可以发现二维相关度可视化结果图更有助于我们挖掘信息。观察图8, 首先发现多数距离中心点较近的点所属集合为紫色集合(其具体对应见图6), 其次我们获得了一些隐含信息:图中黄色点集合多数成员距离中心点较远, 但1、2所标识的客体却与中心点距离较近, 由此体现了1、2的特殊性。然而这种信息在一维相关度可视化结果中是无法被挖掘的。由此可以体现二维相关度更加有利于后期对嫌疑人社交网络信息的挖掘。
本文提出了一种新的嫌疑人社交网络分析方法— — 基于二维相关度的社交网络分析方法, 本文基于手机取证数据, 建立二维相关度模型, 结合数据可视化技术和可视化布局算法, 获得了形象直观的社交网络图。实验证明该方法相较传统方法对嫌疑人与联系人的密切程度的计算更加有效, 对嫌疑人社交网络隐含信息的挖掘更加有效, 更有利于工作人员后期工作的展开, 对于公安工作者分析嫌疑人社交网络有一定实际意义。在本文中, 只对取证数据中的“ 实联系数据” 进行了研究, 并且只开展了围绕单个嫌疑人主体的社交网络分析, 在未来的工作中, 还需研究基于“ 虚联系数据” 的社交网络, 并在不同嫌疑人主体社交网络的碰撞分析方面进行更深入的探究。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|