混合DNA样本的组分数分析
[周密1  , 汪军
, 汪军2, * ]
, 汪军]
|
|


第一作者简介:周密(1982—),男,安徽芜湖人,硕士,主检法医师,研究方向为法医物证学。E-mail:523603361@qq.com
目的 以随机模拟法分析混合样本的表观组分数,探讨混合样本组分数的测算规律。方法 首先,在ID(Identifiler)系统中以随机模拟法分别模拟2~7组分混合样本100万个,统计混合样本表观组分数累积概率(CPA)的分布。其次,自行推导2组分混合样本中表观组分数为1的单基因座概率PA2-1和表观组分数累积概率CPA的公式。继之,设计两组模拟实验,以模拟值对比公式值的方式,分别对两公式进行实验验证。最后,提出非混排除率(PEM)和累积非混排除率(CPEM)概念,以及CPEM的近似值计算公式,计算ID系统的CPEM近似值。结果 本文模拟计算获得了ID系统2~7组分混合样本CPA的分布。自行推导的两个公式均符合模拟实验验证。ID系统中的CPEM近似值为1-1.23298×10-9(0.999999998767)。结论 本文CPA分布及其公式推导在混合样本组分数估测中具有一定的应用价值,建议以累积非混排除率(CPEM)作为单组分样本排除其为混合样本的鉴别指标,所建立的相应近似值计算方法,可用于法医学实践。
ObjectiveTo analyze the apparent component number from the mixed sample of forensic genetic evidence with stochastic simulation for exploring the inherent regularity on the evaluation of the component number of such mixed sample.Methods With stochastic simulation into ID (Identifiler) system, one million STR genotypes of mixed samples, owning 2-7 components, were engendered and analyzed. The distribution of cumulative probability of apparent component number (CPA) in the mixed samples of 2-7 components was calculated by the self-designed software into ID system. Probability formula of apparent component number of the mixed sample, comprising two actual components but showing one apparent component (PA2-1) on a single-locus, was derived along with the cumulative probability formula of apparent component number of mixed sample (CPA) for the multi-loci. The two formulas were then all empirically validated on the calculation values of formula and simulation experiments by correlation method through two sets of simulation experiments. Finally, the concepts were proposed on the probability of excluding mixture (PEM) and cumulative probability of excluding mixture (CPEM). The approximate calculation formula of CPEM was put forward, and tested with the CPEM asymptotic value in ID system.Results CPA distribution of mixed samples owning 2-7 components was calculated with stochastic simulation approach in ID system. Two formulas were all in accordance with the simulation experiments. The approximate value of CPEM was 1-1.23298×10-9 (0.999999998767) in ID system.Conclusion CPA distribution and the formulas built here have certain applicability for the evaluation of component number of mixed sample. The CPEM can be suggested as the appraisal indicator for distinguishing the sample of single component from that mixed, and the method for calculating the CPEM is able to apply into practice of forensic genetics.
法医DNA分析中, 经常会遇到多个体的混合样本, 如犯罪嫌疑人和受害人的混合样品, 或几个犯罪嫌疑人的混合样品。一旦确定为混合STR图谱, 评估混合样本的组分数至关重要。因为组分间的等位基因可能重合, 所以高组分混合样本可能在STR图谱中表现为低组分混合样本。本文以随机模拟法设计100万个2~7组分混合样本对表观组分数进行分析, 并对部分概率进行理论推导和模拟验证。此外, 本文提出非混排除率的概念, 并探讨了累积非混排除率的近似值计算方法。
按随机模拟法, 自主研发软件[1]模拟形成ID(Identifiler)系统的15个常染色体STR基因座的2~7组分混合样本。a.随机个体。在单个基因座上, 随机产生2个等位基因, 组成单个体的基因型, 等位基因的产生概率参考河南汉族人群基因频率的分析和计算[2]。同理分别模拟多基因座, 获得单个体完整STR分型。b.混合样本。根据a, 产生2个随机个体STR分型, 按照混合样本形成规律将两者混合成二组分混合样本STR分型。同理获得2~7组分混合样本STR分型。分别模拟多基因座, 获得2~7组分混合样本完整STR分型。
1.2.1 基本概念
本文的混合样本为理想状态:STR图谱显示混合样本全部基因型, 均为真峰, 忽略伪峰; 不考虑突变率和丢失等例外情况。a.混合样本单基因座表观组分数:混合样本在STR图谱上表现出的由单基因座等位基因数量所决定的组分数量。混合样本单基因座表观组分数=└单基因座等位基因数/2 ┘(└ ┘为向上取整符号)。例如某基因座上混合样本有3或4个等位基因, 则表观组分数为2。b.混合样本单基因座表观组分数概率(PA):混合样本的单基因座上表观组分数在全部理论表观组分数中所占的概率。例如某基因座上, 2组分混合样本的表观组分数可能为1或2, 因此存在表观组分数为1的概率和表观组分数为2的概率, 两者之和等于1。c.最大混合样本多基因座表观组分数:混合样本在STR图谱上表现出的由多个基因座中的单基因座等位基因最大数量所决定的组分数量。d.混合样本多基因座表观组分数=└多基因座中的单基因座最大等位基因数/2 ┘。e.混合样本多基因座某表观组分数累积概率(CPA):混合样本的多基因座上某个表观组分数在全部表观组分数中所占的概率。f.非混排除率(Probability of Excluding Mixture, PEM):表观基因型为单组分样本时排除其为混合样本的概率。g.多基因座非混排除率定义为累积非混排除率(Cumulative Probability of Excluding Mixture, CPEM)。CPEM可作为“ 单组分-混合样本” 识别区分的系统指标, 可根据本文公式(见下面内容)进行定量测算。
1.2.2 PA2-1公式
设N组分混合样本的表观组分数为M时的PA和CPA分别为PAN-M和CPAN-M。下文推导PA2-1、CPA公式和CPEM近似值公式。将混合样本的2个组分分别称之为组分1和组分2。设A1, A2, …, An为一个基因座的n个等位基因, P1, P2, …, Pn分别为各等位基因的频率。设i, j, k为1~n中之任意值(i, j, k = 1~n), 且i < j。设x为非i的1~n全体(x ≠ i), 则Px=1-Pi。
∵ 2组分混合样本的表观组分数=1, ∴ 单基因座等位基因数≤ 2。故, 当组分1的基因型为AiAi时, ∵ 组分2只有为AkAk或AiAx基因型时, 混合样本基因型的等位基因数≤ 2。
∴ 组分1的概率=Pi2, 组分2的二种基因型概率分别为、2Pi(1-Pi), ∴ 合并概率= 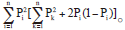
∴ 组分1的概率=2PiPj, 组分2的三种基因型概率分别为Pi2、Pj2、2PiPj, ∴ 合并概率= 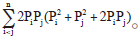
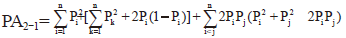
1.2.3 CPA公式
独立遗传的基因座的表观组分数分析为独立事件, 因此根据概率的乘法定律, 多基因座CPA为各基因座PA的连乘乘积, 即:
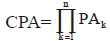
式中, k代表分析的某个基因座, n为基因座数。
1.2.4 CPEM近似值公式
根据CPEM定义, CPEM=1-(2组分混合样本表现为单组分样本概率+3组分混合样本表现为单组分样本概率+…+n组分混合样本表现为单组分样本概率)=1-(CPA2-1+CPA3-1+…+CPAn-1)。
∵ 根据混合样本的原理, 高组分混合样本比低组分更难以表现为单组分基因型, ∴ CPA2-1> > CPA3-1> > …> > CPAn-1。∴ 将CPA3-1, CPA4-1, …, CPAn-1等项忽略, ∴ CPEM≈ 1-CPA2-1 (3)
1.3.1 CPA分析
设模拟数n=100万, 根据1.1方法模拟ID系统的多基因座2~7组分混合样本各n组。根据表观组分数定义, 分别统计ID系统中2~7组分混合样本的各组CPA。例如2组分混合样本, 在每组中如果在15个常染色体基因座上有任意一个基因座的等位基因数≥ 3, 则表观组分数=2; 如果15个基因座的等位基因数均≤ 2, 则表观组分数=1。以n组2组分混合样本的表观组分数为总数, 统计表观组分数为1和2的数量在总数中所占的概率(CPA2-1)与(CPA2-2)。同理统计3~7组分混合样本的CPA。
1.3.2 公式(1)实验验证
设模拟数n=100万, 根据1.1方法在ID系统的各基因座上模拟n个单基因座2组分混合样本。根据表观组分数定义, 统计当表观组分数=1时的PA模拟值(PAS)。例如2组分混合样本在D8S1179基因座上, 如果等位基因数≤ 2, 则表观组分数=1。设模拟实验中所有表观组分数=1的2组分混合样本数量为C, 则D8S1179基因座的PA模拟值(PAS)=C/n。同理可统计所有基因座的PAS。同时根据公式(1)计算ID系统各基因座的PA公式值(PAF), 将PA的模拟值和公式值进行对比。
1.3.3 公式(2)实验验证
设模拟数n=100万, 根据1.1方法在多基因座上模拟n个2组分混合样本, 统计当表观组分数=1时的CPA模拟值(CPAS)。多基因座检验分6组, 其中双基因座: D3S1358+TH01(A组)、 D21S11+D18S51(B组)、 D5S818+D13S317(C组);
三基因座: D7S820+D16S539+CSF1PO(D组)、 vWA+D8S1179+TPOX(E组)、 FGA+D2S1338+D19S433(F组)。即A-C组检验2基因座连乘, D-F组检验3基因座连乘。同时根据公式(1)和(2)计算CPA的公式值(CPAF), 将CPA的模拟值和公式值进行对比。
2.1 2~7组分混合样本CPA
ID系统2~7组分混合样本CPA分布见表1。结果表明, 2~3组分混合样本的绝大部分表观组分数等于实际组分数, 而4~7组分混合样本的表观组份数均低于实际组分数。
ID系统2组分混合样本各基因座的PAF和PAS见表2。结果表明, 各基因座PAF和PAS数值均极为接近, 因此公式(1)符合模拟实验验证。根据PAF和公式(2), 计算得CPA2-1=1.23298× 10-9。
A~F组的PAF和PAS见表3。结果表明, 各组PAF和PAS数值均极为接近, 因此公式(2)符合模拟实验验证。
| 表1 ID系统2~7组分混合样本的CPA分布 Table 1 CPA distribution of mixed samples comprising 2-7 components in ID system |
| 表2 ID系统2组分混合样本的PAF和PAS Table 2 PAF and PAS of mixed samples owning 2 components in ID system |
| 表3 A-F组的CPAF和CPAS Table 3 CPAF and CPAS in groups of A-F |
参考2.2的CPA2-1值和公式(3), 在ID系统中的
CPEM≈ 1-CPA2-1=1-1.23298× 10-9=0.999999998767。即在ID系统中随机抽取2个随机个体组成混合样本, 其STR分型表现为2组分混合样本的概率为0.999999998767, 或者说纯粹由于偶然而表现为单组分样本的概率仅为1.23298× 10-9。
混合样本组分数是混合样本所包含的信息量的重要指标, 不同组分数的混合样本似然率计算方法[3-4]也完全不同, 因此评估组分数是混合样本分析的首要步骤。但相同组分的混合样本在STR图谱上却可能表现为不同组分的混合样本。比如, 两组分混合样本可能在STR图谱上呈现:a.最高3或4个等位基因, 提示为2组分; b.最高1或2等位基因, 提示为1组分。因此2组分混合样本在表观基因型上将呈现2组分或1组分混合样本, 即2组分混合样本有可能表现为单组分样本。再如, STR图谱上呈现的最高4等位基因的混合样本, 虽然提示为2组分, 但实际上可能性还有3组分、4组分或更高组分。因此评估混合样本图谱组分数的难度很大。鉴于混合样本组分数分析非常复杂, 本文从2~7组分混合样本可能的表观基因型概率分布着手, 研究混合样本组分数的内在规律。
混合样本分析主要应用于刑事案件侦查中, 因此本文采用最广泛应用的ID(Identifiler)试剂盒, 具有一定的代表性。因大量混合样本难以获得, 本文的计算和实验均基于随机模拟法产生的近千万个随机混合样本。本文以法医DNA计算器[3]为基础平台, 不仅完美模拟出多组分混合样本, 而且实现了表观组分数的判别和概率分布统计, 体现出随机模拟法在法医DNA领域的帮助作用。
表1结果可见, 2组分混合样本100 %表现为2组分表观型, 同时仅有3.6 %的3组分混合样本可表现为2组分表观型, 而4~7组分混合样本表现为2组分表观型的概率可忽略不计, 因此2组分混合样本的组分数评估风险最低。3组分混合样本96.4 %表现为3组分表观型, 但72.8 %的4组分混合样本、31.9 %的5组分混合样本、9.4 %的6组分混合样本可表现为3组分表观型, 因此3组分混合样本的组分数评估风险大大提高。相对而言, 4~7组分混合样本的组分数表观型相互之间影响很大, 因此4~7组分混合样本无法评估组分数。作者[5]从混合样本似然率计算量的角度, 排除6组分及以上混合样本的分析可能性。本文则首次从组分数评估的角度, 排除4组分及以上混合样本分析可能性。
本文首次阐明的PA和CPA概念在评估混合样本组分数中非常重要。表1中的CPA2-1虽然为0, 但从混合样本的形成机制来看, CPA2-1理应大于0, 只因模拟量过低而无法显示。经本文自行推导PA2-1和CPA计算公式(1)~(2), 并以模拟实验验证, 2.2~2.3结果表明公式(1)~(2)均符合模拟验证实验, 且计算出CPA2-1=1.23298× 10-9, 也即CPA2-1约为10亿分之一, 故而100万模拟量远不足以显现CPA2-1。这不但证实了本文推测, 而且表明CPA2-1完全可以推导其数学公式并获得精确结果。对于表1中其他所有混合样本的CPA, 本文仅获得CPA的模拟值。但参考本文CPA2-1的公式推导, 同理可建立所有混合样本CPA的数学模型, 并因此而获得所有混合样本CPA的精确结果。组分数评估是混合样本鉴定的主要风险之一。对于单组份样本, 本文建议以CPEM作为“ 单组分-混合样本” 的鉴别能力指标, 以定量评估组分数风险。本文仅理论推导出ID系统的CPEM的近似值, 对于其他试剂盒的非混排除率也可同理计算, 而CPEM的数学公式和精确值还有待进一步研究。对于风险较低的2~3组分混合样本, 也应同样建立相应的组分数风险评估指标, 例如非2组分混合样本排除率和非3组分混和样本排除率等。但4组分及以上混合样本的组分数评估风险过高, 应予排除。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|