{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于决策树分析的激光打印文件黑色墨迹量化分析研究
[牟小彬 , 李睿麟, 程卫国]
, 李睿麟, 程卫国]
, 李睿麟, 程卫国]
|
|


作者简介: 牟小彬,高级工程师,硕士,研究方向为文件检验。 E-mail: gaomusihuo@163.com
激光打印文件的量化分析检验一直是个难点。不同种类激光打印机由于制造工艺的差异, 打印文件在墨迹的灰度、打印线条的粗细和粗糙程度、笔画周围散落墨粉点的数量等方面存在差别, 如何通过量化的方法表现这些特征的差异, 以区分不同种类的激光打印机打印文件, 成为亟待解决的问题。ImageXaminer图像扫描分析系统可对打印文件的灰度、线条打印质量、碳粉附着性、色间渗透等参数进行测量, 对打印文件质量进行量化分析。本文运用ImageXaminer图像扫描分析系统, 对打印文件的墨迹微观特征进行量化, 并通过决策树分析方法, 找出与激光打印机种类区分相关性较强的参数项组合, 对量化区分激光打印机打印文件的方法进行探索, 为违法宣传品印制机具的排查比对, 以及添加、换页文件的检验鉴定等案件检验提供新的思路。
选取市场上9个主流品牌18种型号的激光打印机各1台(见表1)。根据激光打印机制作的违法宣传品所具有的黑白打印、同一内容重复出现等特点, 将打印电子文档设置为宋体、黑色、五号字, 内容由案件中常用汉字“ 的、了、法、是、我” 随机组合而成, 使用同一电子文档在同品牌A4幅面纸张上打印文件20页, 分别编号, 共360份样本。使用ImageXaminer图像扫描分析系统(ImageXpert, 美国), 采用800dpi分辨率进行扫描录入样本, 并选取等大的目标区域(regions of interest, 下文简称ROI)对打印文件进行整幅测量。
| 表 1 实验用激光打印机品牌和型号 Table 1 Laser printer brands and models used in the experiment |
ImageXaminer图像扫描分析系统可实现图像增强、图像形态改变、目标区域运算、面积测量、灰度测量、线条、边缘测量、连通区域测量、相关区域测量、霍夫变换算法、向量、文字识别、二维码解码、条纹测量等测量运算。在实验过程中对适用于打印文件整幅测量的参数进行筛选, 发现连通区域测量、灰度测量、面积测量三类参数适用于打印文件整幅测量。连通区域测量是指根据设定的像素极性、灰度阈值、最小测量面积等测量条件, 将待测ROI中的字符划分为若干个连通区域, 并对具有相同明暗极性的连通像素群或由相同明暗极性像素群围成的整块像素群(包括明、暗两类像素)的面积、周长、圆度、背景噪声等微观特征进行量化测量。灰度值测量是指根据设定的像素极性、灰度阈值等测量条件, 对明、暗像素的灰度、明暗线条数量、对比度等微观特征进行量化测量。面积测量是指根据设定的像素极性、灰度阈值等测量条件, 对明暗像素的面积、面积比值等微观特征进行量化测量。
进一步对上述三类参数中反映打印文件灰度、面积、周长、背景噪声等特征参数项进行优选, 筛选出29项测量参数。(1)衡量打印文件灰度特征参数项:有平均灰度、灰度标准差、轮廓平均灰度、轮廓灰度标准差、暗线条数量、明线条数量、暗线条灰度标准差、明线条灰度标准差、暗线条平均灰度、亮线条平均灰度、对称分布值、中位灰度值、灰度众数值、对比度; (2)打印文件面积特征的参数项:面积、面积比值、字块总面积、墨块总面积; (3)打印文件周长特征的参数项:字块总周长、墨块总周长; (4)打印文件背景噪声特征的参数项有背景噪声; (5)打印文件墨迹数量特征参数项:字块数量、墨块数量; (6)综合衡量打印文件面积、打印墨迹数量的参数项:字块面积平均值、字块面积标准差; (7)综合衡量打印文件灰度、打印墨迹数量的参数项:字块灰度平均值、字块灰度标准差; (8)综合衡量打印文件圆度特征(字块线条的粗糙程度)、打印墨迹数量的参数项:字块圆度平均值、字块圆度标准差。
ImageXaminer图像扫描分析系统可以自定义灰度阈值及测量的面积范围, 为了更加全面的、恰当的反映打印样本的情况, 本实验对测量条件进行了如下设置:
1.3.1 灰度阈值设置
由于打印机品牌、型号、使用环境等相关因素的影响, 打印件打印文字墨迹粉堆积感及底灰不同, 简单来说, 就是人眼观察到的颜色深浅不同; 从图像上来说, 就是墨迹的灰度不同。在灰度图像中的每个像素都是从0~255的亮度值, 通常把0定义为“ 黑” , 255定义为“ 白” 。阈值就是临界值, 是基于图片亮度的一个分界值, 默认值是50%中性灰(即128), 也就是当选择灰度阈值为128时, 亮度低于128的即被认为“ 黑” , 在利用系统对打印件相关参量的测量中, 可以自行定义阈值, 而阈值的确定决定了准入计算的亮度值。一般在阈值较小的情况下, 墨粉浅淡的笔画不参与计算; 在阈值较大的情况下, 可以充分地识别墨点, 但有时也会把纸张上的深色纤维点算入, 阈值过大, 超出了样本的最大灰度极限, 则无法测量。
系统会根据阈值选择所测部分, 阈值设定不同, 同一参数的测量值会随之变化, 如针对同一张样本, 对字块面积平均值参数进行测量, 设定最小测量面积为1, 当灰度阈值设置为80时测量值为0.117, 当灰度阈值设置为117时测量值为0.18, 当灰度阈值设置为128时测量值为0.198, 当灰度阈值设置为160时测量值为0.161。为了全面反映各样本的量化测量情况, 实验中选择亮度较深的80, 此时一些浅淡的笔画不参与计算; 中间值117, 此时笔画周围的散落墨粉点基本不参与计算; 默认值128, 此时笔画周围的散落墨粉点大部分参与计算; 亮度较浅的160, 此时除笔画周围的散落墨粉外, 页面上的散落墨粉点和疵点也参与计算, 共4种阈值设置。
1.3.2 最小测量面积设定
打印机墨迹的连通区域测量过程中可以自定义参与计算的最小墨迹面积, 该设置最小面积定义为≥ 1, 即1为最小的数量级, 系统默认最小值为100, 可自行设定任意值。系统会根据最小测量面积选择参与测量的墨点, 最小准入测量面积不同, 同一参数的测量值也会随之变化。如针对同一张样本, 对字块面积平均值参数进行测量, 设定灰度阈值为128, 当最小测量面积为1时测量值为0.198, 最小测量面积为1时测量值为0.149。但当选择系统默认最小值100时, 背景噪声为0, 无法测量, 为了充分反映笔画周围的细微墨点分布情况, 实验中选择最小测量面积为系统最小值1。根据上述测量条件设置, 测量参数共计29项116组。
本实验收集打印样本360份, 每份样本具有116个属性, 并已知每个样本的分类标号(样本属于哪一台打印机), 可以通过“ 监督学习” 的分类算法建立分类模型。“ 监督学习” 分类算法比较著名的有决策树, 朴素贝叶斯, 神经网络, 支持向量机等。这些算法里, 决策树学习算法是最广泛应用的一种方法, 这种算法的分类精度与其他算法相比具有相当的竞争力, 并且十分高效。支持向量机具有很好的鲁棒性, 计算复杂性不取决于维数, 因此避免了“ 维数灾难” , 但是它对于大样本分类和多分类问题存在不足。神经网络具有非常强的非线性拟合能力, 但是它最大的缺点即是缺乏解释能力。朴素贝叶斯的前提条件太过严苛, 需要属性之间具有独立性。所以, 针对本实验的特点, 选择决策树模型作为分类方法。常用决策树算法有ID3算法和C4.5算法, 下面依次介绍这两种算法。
2.1.1 决策树算法简介
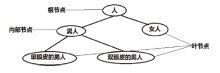
决策树是一种由节点和有向边组成的树状结构, 树中包含三种节点(见图1):1、根节点, 没有入边, 但有零条或多条出边; 2、内部节点, 有一条入边和两条或多条出边; 3、叶节点或终节点, 有一条入边, 但没有出边。决策树中每个非叶节点表示一个特征属性的测试, 每个分支代表这个特征属性在某个值域上的输出, 而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始, 测试待分类项中相应的特征属性, 并按照其值选择输出分支, 直到到达叶节点, 将叶节点存放的类别作为决策结果。
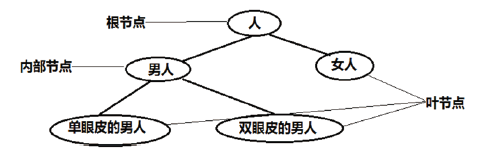 | 图 1 决策树节点示意图Fig.1 The nodes in a decision tree |
构造决策树的关键步骤就是分裂属性。分裂属性就是在某个节点按照某一特征属性的不同划分构造不同的分支, 其目标是让各个分裂子集中的待分类项属于同一类别。构造决策树的关键性内容是进行属性选择度量, 属性选择度量是一种选择分裂准则。属性选择度量的算法有很多, 一般使用自顶向下递归分治法, 并采用不回溯的贪心算法, 著名的有ID3算法和C4.5算法。
2.1.2 ID3算法原理
ID3算法的核心思想就是以信息增益度量属性选择, 选择分裂后信息增益最大的属性进行分裂。基本概念如下:设S为用类别对样本空间的划分, 则S的熵定义为: 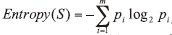
现假设样本空间S按照属性A进行划分, 则A对S划分的期望信息为: 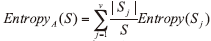
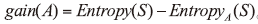
2.1.3 C4.5算法原理
C4.5算法相比于ID3算法最主要的改进即是分裂属性的选择由根据信息增益变为信息增益率, 信息增益率的计算过程如下:
首先定义分裂信息: 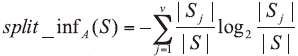
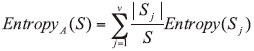
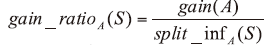
C4.5选择具有最大信息增益率的属性作为分裂属性。C4.5算法产生的分类规则易于理解, 准确率较高。因此, 选择决策树C4.5算法作为模型建立的方法。
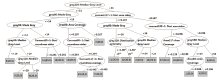
对18台激光打印机360页样本进行连通区域测量、灰度测量、面积测量, 对阈值设置分别为80、117、128、160时, 测量所得的29项参数116组测量数值应用决策树学习算法对其进行分类, 训练出的决策树模型见图2。
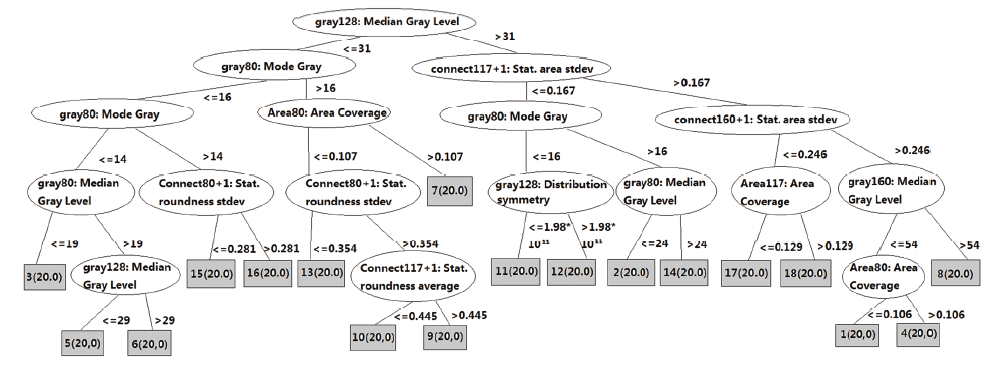 | 图 2 决策树模型。(A) 阈值为128的中位灰度值; (B)阈值为80的灰度众数值, 阈值为117、最小测量面积为1的字块面积标准差; (C)阈值为80的灰度众数值, 阈值为80的面积比值, 阈值为80的灰度众数值, 阈值为160、最小测量面积为1的字块面积标准差; (D) 阈值为80的中位灰度值, 阈值为80、最小测量面积为1的字块圆度标准差, 阈值为80、最小测量面积为1的字块圆度标准差, 阈值为128的对称分布值, 阈值为80的中位灰度值, 阈值为117的面积比值, 阈值为160的中位灰度值; (E) 阈值为128的中位灰度值, 阈值为117、最小测量面积为1的字块圆度平均值, 阈值为80的面积比值。Fig.2 Decision tree. (A) gray128: Median Gray Level; (B) gray80: Mode Gray, connect117+1: Stat. area stdev; (C) gray80: Mode Gray, Area80: Area Coverage, gray80: Mode Gray, connect160+1: Stat. area stdev; (D) gray80: Median Gray Level, connect80+1: Stat.roundness stdev, connect80+1: Stat.roundness stdev, gray128: Distribution symmetry, gray80: Median Gray Level, Area117: Area Coverage, gray160: Median Gray Level; (E) gray128: Median Gray Level, connect117+1: Stat.roundness average, Area80: Area Coverage. |
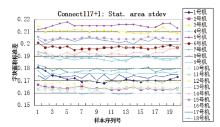
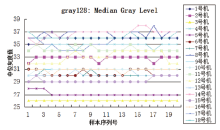
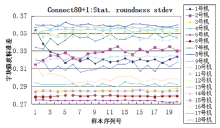
从实验结果中可以看出:使用阈值为128的中位灰度值, 阈值为80的灰度众数值, 阈值为117、最小测量面积为1的字块面积标准差, 阈值为80的面积比值, 阈值为160、最小测量面积为1的字块面积标准差, 阈值为80的中位灰度值, 阈值为80、最小测量面积为1的字块圆度标准差, 阈值为128的对称分布值, 阈值为117的面积比值, 阈值为160的中位灰度值, 阈值为117、最小测量面积为1的字块圆度平均值等11组参数, 能够分类18台激光打印机的打印样本, 经测试集测试分类正确率达100%, 且得到的决策树只有6层, 结构简单, 上述11组参数对于实验用18台打印机的分类具有较强相关性, 可以正确区分本实验中的9个品牌18种型号共18台激光打印机360页打印样本。18台不同型号的打印机连续打印的20页样本, 虽然在单个参数上存在数值交叉的现象, 但是通过11组参数组合可以区分。如, 虽然3号机与5号机在阈值为117、最小测量面积为1的字块面积标准差中存在数值交叉(见图3), 但是通过阈值为128的中位灰度值可以区分(见图4); 2号机与12号机在阈值为128的中位灰度值中存在数值交叉(见图4), 但是通过阈值为80、最小测量面积为1的字块圆度标准差可以区分(见图5)。另外, 通过上述实验也发现在连通区域测量时, 阈值设定为160, 部分样本超出了其测量的阈值, 该样本无测量值, 数值显示为0, 一旦出现这种情况, 则应舍弃该参数值。
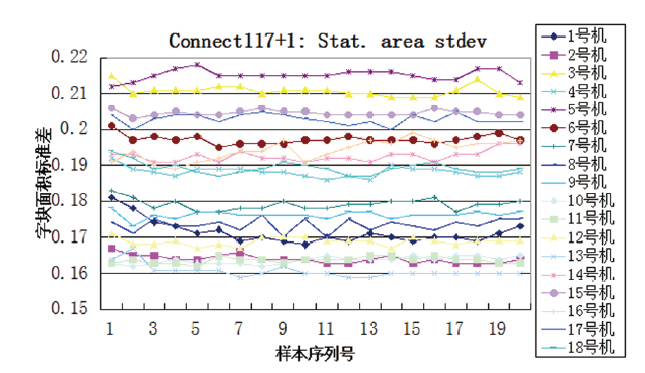 | 图 3 阈值为117、最小测量面积为1的字块面积标准差Fig.3 Stat. Area Stdev threshold of 117 and minimum area of 1pixels |
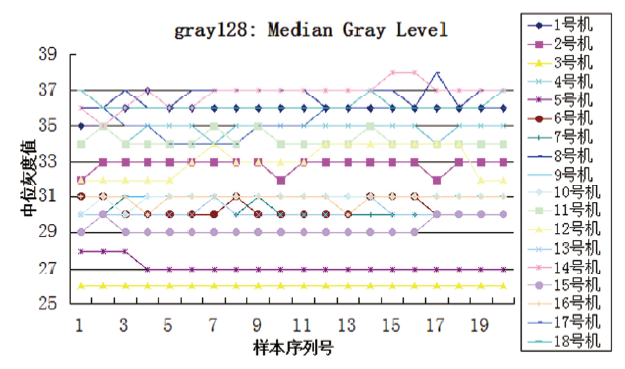 | 图 4 阈值为128的中位灰度值Fig.4 Median gray lever threshold of 128 |
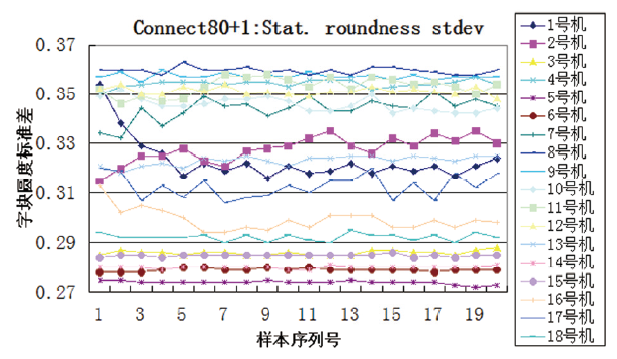 | 图 5 阈值为80、最小测量面积为1的字块圆度标准差Fig.5 Stat. roundness Stdev threshold of 80 and minimum area of 1pixels |
本实验中筛选出的与激光打印机分类相关性较强的11组参数是中位灰度值、灰度众数值、字块面积标准差、面积比值、对称分布值、字块圆度标准差、字块圆度平均值等7项参数在不同阈值下的参数组合, 从参数所衡量的打印文件特征中可以看出不同激光打印机打印样本在灰度、面积、圆度、打印墨迹数量等特征及特征的组合上存在差别, 可以用于不同种类激光打印机打印样本。从决策树模型分类结果中可以看出, 5号机(惠普P2055d)与6号机(惠普M401dn), 9号机(兄弟HL-2250DN)与10号机(兄弟HL-2240D), 11号机(理光SP310DN)与12号机(理光SP200), 15号机(柯尼卡美能达 MAGICOLOR 1650EN)与16号机(柯尼卡美能达 MAGICOLOR 1700W), 17号机(京瓷FS-1040)与18号机(FS-1060 DN)的样本在接近树的底层才被区分开来, 说明同品牌相近类型的打印机在主要的分类属性上具有很强的相关性。
本实验通过9个品牌18种型号共18台激光打印机360页打印样本进行实验研究, 发现不同激光打印机打印样本在阈值为128的中位灰度值等11组参数上具有特殊性和相对稳定性, 通过11组参数组合可以区分不同种类激光打印机打印样本, 通过量化方法区分激光打印机打印样本具有可行性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|