



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
指纹特征点区域分布规律应用研究
[张宇 , 吴春生, 孙忠, 冯才刚]
, 吴春生, 孙忠, 冯才刚]
, 吴春生, 孙忠, 冯才刚]
|
|


作者简介:张宇(1974—),女,北京市人,工程师,本科,主要从事指纹检验鉴定和指纹管理工作。Tel:13521101826;E-mail:libra.rain@hotmail.com
目的 针对指纹自动识别系统评分机制所存在的局限性,探讨根据指纹特征点分布进行加权的方法。方法 通过总结大量人群指纹特征点区域分布规律,按照分布密度在计算中进行加权。结果 在对反查指纹加权计算的试验中,同一指纹加权后的分数相比其它指纹得到了提高。结论 采用此种加权机制,对于现有基于特征点的指纹自动识别系统准确率提高是有效的。
Objective To analyze the limitation of scoring mechanism used in automatic fingerprint identification system and explore a weighted method based on fingerprint feature point distribution. Methods A large group of fingerprints (12 million people) were studied and distribution regularity of fingerprint feature points was summarized. According to the density distribution of fingerprint feature points, the weighted factors were added into the score. Results The test matching was conducted and the results demonstrated that the weighted score of same fingerprint compared to other fingerprint was improved. Conclusions This weighted scoring mechanism based on fingerprint feature point distribution is effective for accuracy improvement of automatic fingerprint identification system.
目前各国对于大批量的指纹比对检验工作均采用计算机指纹自动识别系统完成。不论是人工进行检验还是计算机自动识别目前主要方式是采用指纹特征点识别方式, 既通过对两枚指纹特征点的重合程度判断两枚指纹为同一枚指纹的可信度。两指纹间对应上的特征点越多, 对应点之间的位置、角度误差越小则可信度越高。
目前的指纹自动识别系统中, 指纹比对相似度判断对于所有特征点的作用权值即贡献率是相同的, 也就是在计算中每个特征点对于两指纹是否同一的贡献是相同的。在这种规则下, 即使一个非常有特殊性的点比对上也只是和一个出现频率很高的点比对上同样对待。在人们通常认识中, 如果档案指纹和另一枚指纹进行相似度比较, 那么确实是应该按照其比对结果的相似程度从大到小进行排序。但实际上特征点对应上的多相似度不一定就高。实际上指纹不同区域的特征点分布并不是均匀的, 如在中心、三角区域分布的相对密集、在边缘或稀疏区分布的相对较少[1]。同时特征点角度的取值也是随区域不同呈现一定的规律性变化。因此, 将所有特征点同等对待就没有办法体现出因为特征点分布位置、角度的不同所带来的个体差异的特殊性, 即单纯的以特征点对应上的多少确定两指纹的相似度分数在某些情况下存在一定的局限性[2]。
在目前的指纹自动识别系统核心算法中, 也是按照两枚指纹特征点对应的数量决定其比对的分数。只是根据特征点之间的位置关系、角度关系进行了相应的加权。但是在实际指纹特征点的比对中经常出现分数很高, 但经人工分辨排除, 而排在后面分数低一些的却可以认定同一的情况, 如例1正查比对情况(见图1~图3)。可以看到, 认定同一的指纹排名第35位, 且分数比第一名有一定差距。究其原因, 排除比对算法自身问题和现场指纹特征点标注过程中的误差以及指纹轻微变形原因, 很大程度上是由于指纹之间的特征点相似度较高造成的。分析原因可得出, 由于目前指纹自动识别系统普遍采用的是每个对应特征点相同权值的评分方法, 因此当两个或多个档案指纹都有部分特征点与现场指纹大部分特征点相似时会产生两者得分相同或相近情况。而当比对算法考虑一些特征点位置相对关系时, 会由于较多随机因素出现同一的指纹得分较低的情况。由上述例子可以看出, 采用特征点相同权值的评分机制在某些时候无法解决现场比档案时, 因为不同档案对应特征点数量相近的问题。而对于档案比对现场情况(反查), 则问题更加突出, 如例2(见图4~图5)。
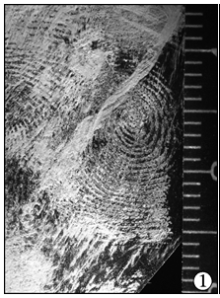
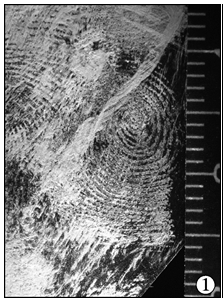 | 图1 现场指纹; |
 | 图2 排名1分数1120; |
 | 图3 排名35 分数860 |
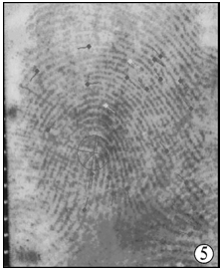
 | 图4 档案指纹; |
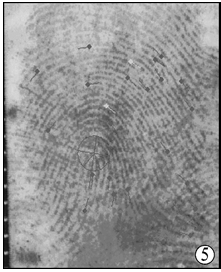 | 图5 排名第一现场指纹, 分数1131; |
 | 图6 现场同一指纹, 排名10分数917 |
从图6看到, 虽然现场同一指纹所有特征点均能与档案对应, 但分数却明显少于排名第一现场指纹。分析原因, 主要是由于二者提取到的特征点数量不同, 特征点多的其对应点的最大数量也就多。在此情况下, 即使同一指纹能够与所有特征点实现匹配, 但如果提取到的特征点绝对数量偏少, 还是会出现上例中的情况, 因绝对特征点较少而不能得到较高评分。
目前在实际人工比对中, 有经验的专家对两枚指纹进行认定时通常是按照经验寻找其相对特殊的点位, 如特殊位置、特殊角度、特殊类型、特殊组合等, 而不是任意8点即可进行认定[3]。可见从专家经验角度看各个特征点的作用也不是相同的。但是在指纹自动识别过程中尚不能实现对于特征点类型和组合的分辨而只能区分位置和角度。因此, 在沿用现有方法的基础上, 需要讨论一种按照特征点不同位置、角度分布密度进行分数加权的评分机制。即按照大量的社会人群中指纹在某一位置的特征点分布多少来决定比对特征点所应具有的分数权值。也就是说, 当两指纹对应的某个特征点在社会人群中分布较多时, 此特征点对最终比对分值的贡献就应该相对减小; 当两指纹对应的某个特征点在社会人群中分布较少时, 此特征点对最终比对分值的贡献就应该相对增大。
通过将新的规则与原有自动识别系统中分数计算规则来进行比较, 最终结果只能有3种:分数升高、分数不变、分数降低。当两枚指纹之间对应上的特征点多数都比较普遍时那么会出现分数降低的情况; 当对应上的特征点有较多的少见特征点时会出现分数升高的情况; 当情况适中时分数会基本保持不变。
对于待比对指纹, 其某个特征点能否与指纹库中任意指纹存在对应点的概率与此点在大范围人群指纹同一位置中的分布情况相关。分布越多存在对应点的可能性越大, 分布越少存在对应点的可能性越小。因此, 待比对指纹比对结果除自身外的一般规律是:待比对指纹中分布概率大的特征点位其在档案库中找到的具有对应点的指纹多, 反之则少。
对于同一的两枚指纹来说, 两者间各个特征点在比对时能否对应上只与采集的质量有关, 与特征点分布概率情况无关, 因此对于那些出现相对较少的稀少特征点也可以实现很高的比中率。为此, 同一指纹比中的稀少特征点概率相对非同一的指纹要大, 也就比非同一的指纹能够得到更高的权值。
需要特别注意的是, 上面提到的分数上升、下降只是一个相对的概念。因为指纹工作者关心的重点是能否将一枚指纹与自身比对和与其他指纹比对的结果差距拉开。如, 当待比对指纹的特征点分布概率普遍较小时应用此方法时会出现分数普遍上升的情况, 但此时其同一的比对结果分数则可能会出现分数大幅上升的情况, 反之亦然。
基于特征点分布率加权方法的基础工作是计算出整个指纹区域的特征点分布数量, 即特征点分布密度, 这就需要对人群整体的指纹特征点分布情况进行综合统计。从统计学角度讲, 当个体的数量达到一定的规模, 其所表现出来的规律特性就可以看作是整体的特性[2]。选取北京市公安局指纹数据库中约1200万人的全国十指指纹档案数据作为计算指纹特征点分布的基础数据。在北京市刑科所CAFIS指纹系统中对于特征点提取的操作程序基础上, 编写程序软件对上述指纹数据进行分析, 基本计算思路如下:
(1)首先读入档案中特征点数据文件, 进行结构转换等预处理。
(2)剔除提取质量不好以及无中心点的指纹数据。
(3)由于需要按照统一的坐标系来进行计算, 因此对所有指纹进行坐标变换, 包括位置坐标和角度, 将指纹整体移动使指纹中心位于统计区域中心并且旋转角度使指纹中心角度处于竖直方向。考虑到捺印时中心点的偏差, 取坐标系的有效区域为800* 800像素。
(4)以每个像素作为基本统计区域, 对坐标系中位于每像素点上的特征点进行累加并记录。考虑误差原因, 可将基本统计区域进行扩展。
(5)根据上步计算的结果得出整个指纹库中概率分布的数组并输出到文件。
采用上述步骤对1200万人的指纹库进行统计, 得到概率点分布数组数值, 从其中可以看出随着位置、角度的变化其数值曲线过渡平滑、无明显拐点和突变, 这也印证了特征点的分布具有规律性。通过以上计算后得出的概率分布数组文件在进行数学归一化后即可用于分数权值的计算应用。具体归一化方式需要根据不同指纹比对算法情况经试验后制定, 本文暂时采用除以代数平均值再乘方的方法进行计算。编写供指纹系统调用的接口函数, 在指纹比对主程序中对其进行调用。当输入一个坐标、角度参数时即可得到该点对应的权值数据。
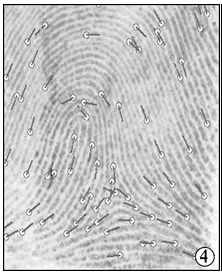
比较本文例2中比中特征点对应情况(见表1)。工作中要做的就是将表1中对应上的特征点位置按照标准坐标系转换后从整个特征点分布图中找到所对应的位置, 根据数值多少决定此点的权值大小, 最后得出总的分值。
经调用概率分布数组, 得到档案指纹每个指纹点对应的数值分布情况, 列举出本文示例2所需部分特征点对应分布数值和权值(见表2)。
| 表1 例2指纹比对特征点对应 |
| 表2 各特征点对应权值 |
由表2可见, 虽然特征点少, 但认定同一的指纹相比排第一位的指纹具有更高的权值。因此, 在采用此种加权机制情况下, 其实际得分将比原来有一定程度的提高。此结果表明按照指纹区域分布规律对特征点进行权值计算并应用到指纹自动识别系统分数计算的方法是切实有效的。进一步, 还可以对十指档案中不同指位、纹型的特征点分布情况进行分析, 这样可以更加有针对性的对特定指位、纹型的特征点分布规律进行统计, 使得最后的结果更加准确。
The authors have declared that no competing interests exist.