







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
海量数据取证方法的探讨
[李荣荣 , 吴春生]
, 吴春生]
, 吴春生]
|
|


作者简介:李荣荣(1979—),女,山西人,工程师,硕士,主要从事电子物证专业的研究和检验鉴定工作。Tel:010-83996730;E-mail:lirongrong_xks@163.com
目的对当前我国电子物证检验中提取到的海量数据信息的取证难题进行探讨。方法对数据文件中海量数据信息的特点及其传统取证方法进行分析研究。结果提出开发专用工具软件进行海量数据文件的提取。结论利用专用提取工具软件可以对常见数据文件中有规律性的数据内容进行读取、计算、查重和汇总,使海量涉案数据文件的检验从传统的人工方式转变为计算机的自动处理。
Objective To investigate the method for massive data information extraction in examination of electronic evidence.Methods The characteristic of the massive data files and traditional evidence extraction method was analyzed.Results The development of special software for information extraction from massive data was suggested.Conclusion With the special software, the traditional artificial method can be changed.
目前在我国司法鉴定机构的电子物证检验方面, 普遍存在着对大量数据文件中海量数据信息的取证难题[1, 2]。近年来由于利益的驱动, 非法获取和倒卖公民个人信息的犯罪层出不穷, 并呈现快速上升的趋势。网络技术和数据库技术的发展为这些成百上千万数据的收集和扩散提供了有利条件。此类案件的侦破过程中, 涉案计算机中所存储的海量的公民信息数据成为重要证据。此类检验需要对大量的涉案数据文件逐一确认并进行统计, 但是由于当前电子取证方面的硬件设备(如:硬盘克隆机、便携式现场取证设备、硬件分析解码设备等)和软件产品(如:Encase、X-Ways、FTK等电子数据综合分析取证软件, Easy Recovery、final data等数据恢复软件, 各种密码破解等专用软件等)对于文件内部海量的同类信息记录数的统计汇总均不能实现。这就只能采用手工的方式将涉案文件逐一打开确认并计算, 不仅效率低下, 而且容易出错。在涉及海量数据时, 此类体力密集型的工作经常面临找到了证据文件但无法统计出有效数量而无法按时完成的尴尬。因此, 提高对各种类型文件内部海量数据信息快速有效的提取检验能力成为电子证据检验部门和检验人员的当务之急。
软件:Windows XP操作系统、Microsoft office 2003、通用数据库软件。
硬件:计算机(双核CPU、4G内存, Windows XP操作系统)。
数据:使用电子取证软件从存储介质中提取到的大量数据文件中的海量数据信息。
通过对近年来涉及海量数据提取的案件检验的分析总结, 发现此类数据文件有下列特点:第一, 文件类型主要有txt文本文件、excel表格文件、可执行文件、word文档和access数据文件。
(1)txt文本文件:即纯文本文件, 其格式简单透明, 不含结构信息和加密, 能用基本文本编辑工具阅读[3]。海量数据通常采用按行存储的方式, 每行一条独立完整的记录, 每行有固定的数据项, 各个数据项之间有统一的分隔符进行分隔(见图1)。
 | 图1 txt文本文件 |
(2)excel表格文件:Microsoft Excel是Microsoft office的组件之一, 是办公自动化中非常重要的一款软件, 多用于进行数据管理[4]。数据在excel表格中按照行和列的方式存储, 每行一条独立完整的记录, 每列的值属性相同(见图2)。
 | 图2 excel表格文件 |
(3)可执行文件:可执行文件可以加载到内存中, 并由操作系统加载程序执行。它可以是 * .exe文件、* .sys文件, * .com文件等(见图3)。
 | 图3 可执行文件 |
(4)word文档:Word是由Microsoft公司出版的一个文字处理器应用程序, 也是Microsoft Office的一部分[3], Word软件提供了强大的制表功能, 不仅可以自动制表, 也可以手动制表。海量数据在Word中也主要以表格的形式存在(见图4)。
 | 图4 word文档 |
(5)access数据文件:access是由Microsoft公司发布的关联式数据库管理系统, 也是Microsoft Office的一部分[3], access软件提供了强大的数据管理功能。海量数据在access中主要以数据库表的形式存在(见图5)。
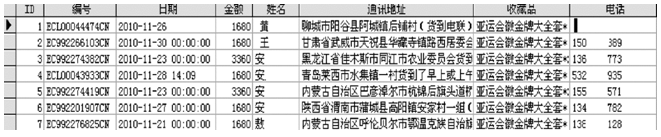 | 图5 access数据文件 |
可执行文件的统计可以通过操作系统自带的工具实现, word文档生成的表格具有较强的随意性和灵活性, 所以本文暂不将这两种文件作为考虑对象。
第二, 文件内容主要包括帐号、个人信息、物品信息和行为信息。
(1)帐号:存储的内容主要是账户和密码信息;
(2)个人信息:存储的内容为姓名、身份证号、电话、住址等信息;
(3)物品信息:存储的内容主要涉及到物品相关的信息;
(4)行为信息:存储的内容主要是人与人或人与物之间的行为, 如交易信息、网页浏览信息等。
上述各类文件的读取要点和读取方式分别是:
(1) txt文本文件的行数没有限制, 但是其文件大小会受操作系统的限制。如unix系统下单个文本文件不能超过2G, windows下FAT32文件系统也不能超过2G。文本文件中不含结构信息, 每行为一条记录, 以“ 0D0A” 作为每行的结束符。图6是在Winhex软件中打开的文本文件, 从中可以直观地看到它的文件结构。
 | 图6 Winhex软件中打开的文本文件 |
(2)excel表格文件最多允许256列, 65536行。可以直接打开文件, 直观的对数据进行统计。
(3)access表的大小最大为2G字节(office 2000版以后), 表中字段的个数为255。可以利用SQL 语句对一个或一个access表的数据进行统计。由于access是桌面数据库, 最好单个表的记录数限制在10万条以内, 否则性能大大降低。
如上所述, 对于excel文件和access文件, 可以实现对数据的统计。对于文本文件, 最常用的方法是将检出的文本文件导入到excel中, 利用excel的数据“ 数据” 菜单, 选择“ 导入外部数据-导入数据” , 选择相应的文本文件作为数据源, 按照文本导入向导进行, 见图7和图8。检出的文本文件见图9。导入到excel中后见图10。
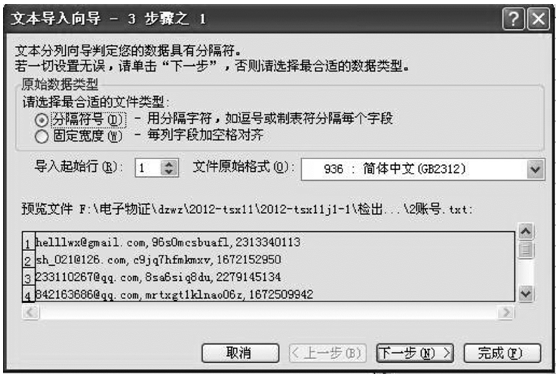 | 图7 excel中的文本导入向导 |
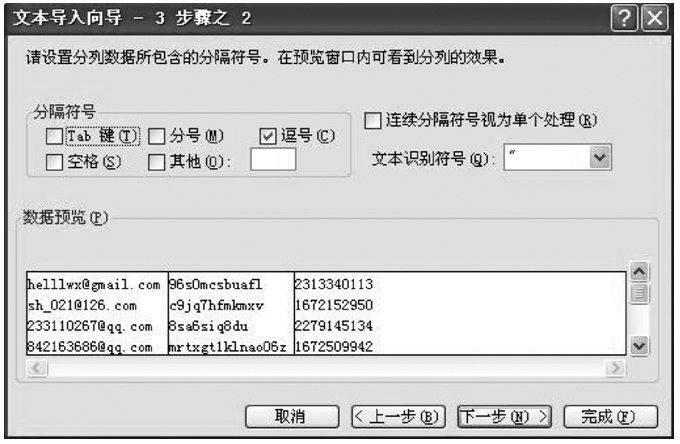 | 图8 excel中的文本导入向导 |
 | 图9 文本文件内容 |
 | 图10 导入excel后的文件 |
这样, 利用excel的数据统计功能, 可以直观的统计出此文本文件中的记录数。如果检出了多个这样的文本文件, 检验人员需要重复多次上述的步骤, 然后将各个excel文件中的记录数进行汇总, 对于检验人员来说, 是一项费时费力的重复性劳动。如果这样的文件多达成百上千个, 势必会影响案件的检验周期, 甚至根本无法准确计算。
在对检出文件进行研究分析的基础上, 可开发一个供检验部门直接使用的海量数据文件内容提取工具软件, 实现对常见的数据文件中有规律性的数据内容进行读取、计算、查重、汇总[5]。
(1)文件分类。通常, 同一案件检出文件的内容结构基本相同, 对于结构不尽相同的文件, 软件可以对检出文件的内容进行逐一搜索, 按照结构对文件进行自动分类。软件同时提供对文件的手动分类功能, 检验人员可以根据工作需求决定文件如何分类。
(2)建立数据库表。软件可以对案件进行管理, 一个案件对应数据库中的几个表, 表的结构根据文件的结构而定, 文件的分类数量决定一个案件中表的数量。这些表用于存储检出文件的数据内容。
(3)数据导入到数据库中。提供批量导入文件到数据库中的功能, 用户只需要指定文件所在的路径, 程序可以将该路径下所有的文件自动导入到数据库中。
文件读取入库主要有以下2种方式:
方式1:程序从文本格式的数据文件中一次读出一条或多条记录, 执行SQL语句插入到数据库表中;
方式2:编写存储过程, 将数据导入到数据库中。
推荐采用存储过程的方式导入数据, 因为存储过程在创建时就被编译和优化, 在以后的调用就不必再进行编译, 可以加快程序的运行速度。此外, 存储过程创建好后被存储在数据库中, 可以被很多用户重用和共享。对存储过程的修改可以不影响源程序。
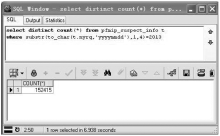
(4)统计功能。对数据的统计是软件的重点, 即对已经导入的数据库的数据进行分析。数据库在数据的查询统计方面有先天的优势, 可以对导入的数据进行分类汇总, 并直观地显示。图11是oracle数据库DBMS中的统计语句及统计结果示例。在专用的取证软件中可通过将SQL语句进行封装在软件内实现统计功能。
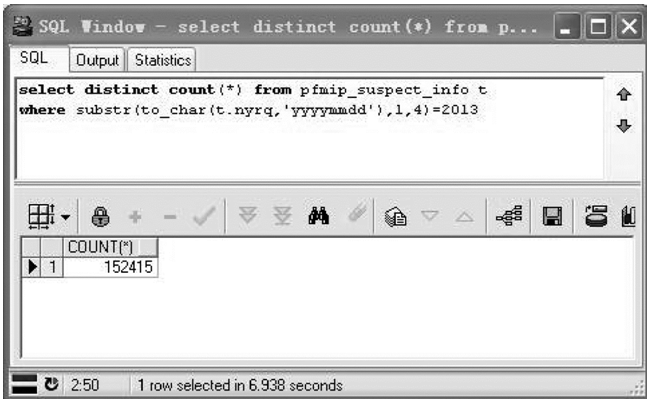 | 图11 数据库统计示例 |
(1)程序架构的设计。程序可以采用C/S或B/S的架构, 但无论采用哪种架构, 都应考虑到充分发挥服务器高效的处理能力和快速的读写能力, 来处理客户端提出的请求。客户端只用来提交请求和显示服务器端处理的结果。这样程序的处理速度可以得到大幅提高。
(2)数据的统计功能设计。用户在进行数据统计工作时, 遇到统计数据量特别大的情况, 往往需要花费较长的时间来完成统计。本软件对数据信息的汇总, 可实现边导入边计数的方式, 将汇总结果存储到数据库表的相应字段中。这样, 在程序汇总该数据时, 只需从数据库中读取出该条记录即可。如:在软件中共导入2万条数据, 将“ 20000” 记录在专门的数据库表字段中, 每次执行统计时, 程序只需从相应的表中读取这个记录即可, 大大提高了数据的统计速度。
(3)界面设计。当程序处理的数据量特别大的时候, 可能出现“ 假死” 状态, 用户会觉得系统运行速度很慢。为避免这种情况, 可以在程序设计时, 在程序界面上实时刷新数据, 显示正在处理的数据信息, 这样, 用户会看到有不断的数据变化, 表明程序正在快速处理数据。
(4)日志记录。程序在处理文件中的数据时, 要进行日志记录, 便于检验人员查看和确认数据是否正确入库。
当前司法鉴定机构在电子证据检验中, 对于文件中海量数据的统计分析, 在人力无法完成的情况下, 尚没有形成一套用于电子取证领域的大量多数据源的数据文件中数据综合提取统计分析的知识体系和实用工具。本文提出开发专用的数据取证工具, 自动将存放数据的文件批量的导入数据库之中的方法。该工具可对提取数据直接进行简单统计, 也可以使用数据库管理系统(DBMS)工具进行相关数据操作, 达到对数据进行分析统计地检验目的。该方法使得检验人员无须具有较高的数据库知识和操作技能就能灵活应用。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|